
Paper Reading: Embodied AI 9
从一些 Embodied AI 相关工作中扫过。
Cosmos Policy#
直接把 Cosmos-Predict2 后训成 Policy 的 WM-VLA
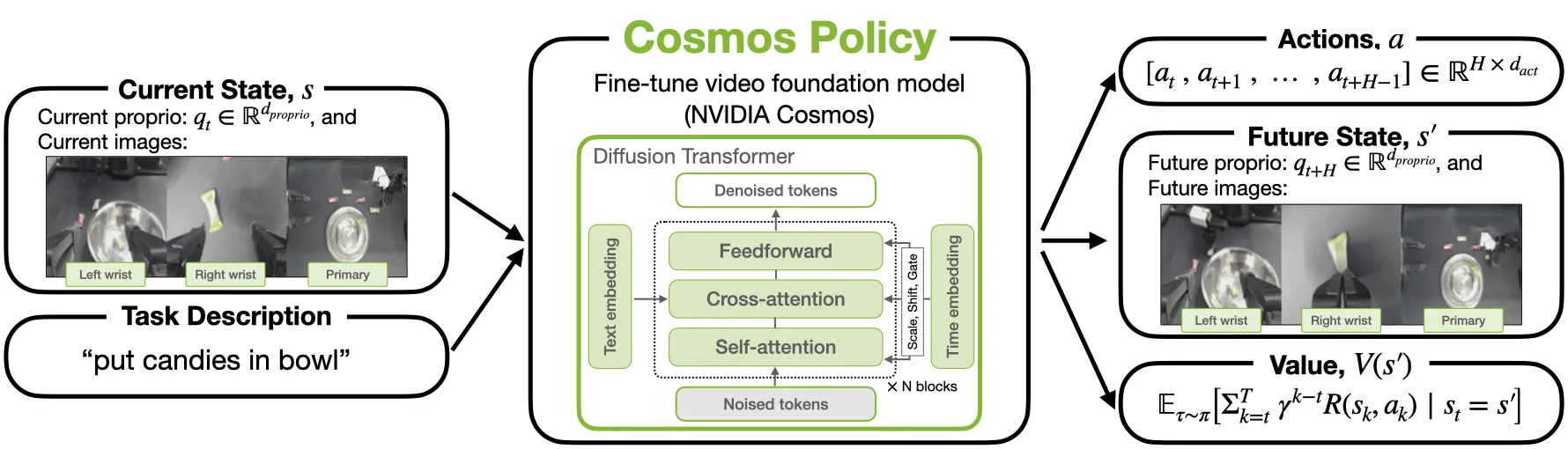
Cosmos Policy 使用 Cosmos 作为预训练的模型,然后直接让其同时预测不同的内容,除了之前就需要预测的 frame,也包括预测 Value 以及 Action 的信息。本身从实现上来说感觉没什么问题,做法也比较简单粗暴,从实际上来说作者们也承认这基于 Cosmos 可以直接建模 Action 这个假设,而这个假设大概率是不成立的。不过总归我们需要这样一个一股脑梭哈的模型,从而才可以在和其他精心设计的模型的对比中寻找真正关键的 insight,本身做的也比较干净,值得一读。
BayesianVLA#
Bayesian 分解防止 VLA 把语言当冗余输入
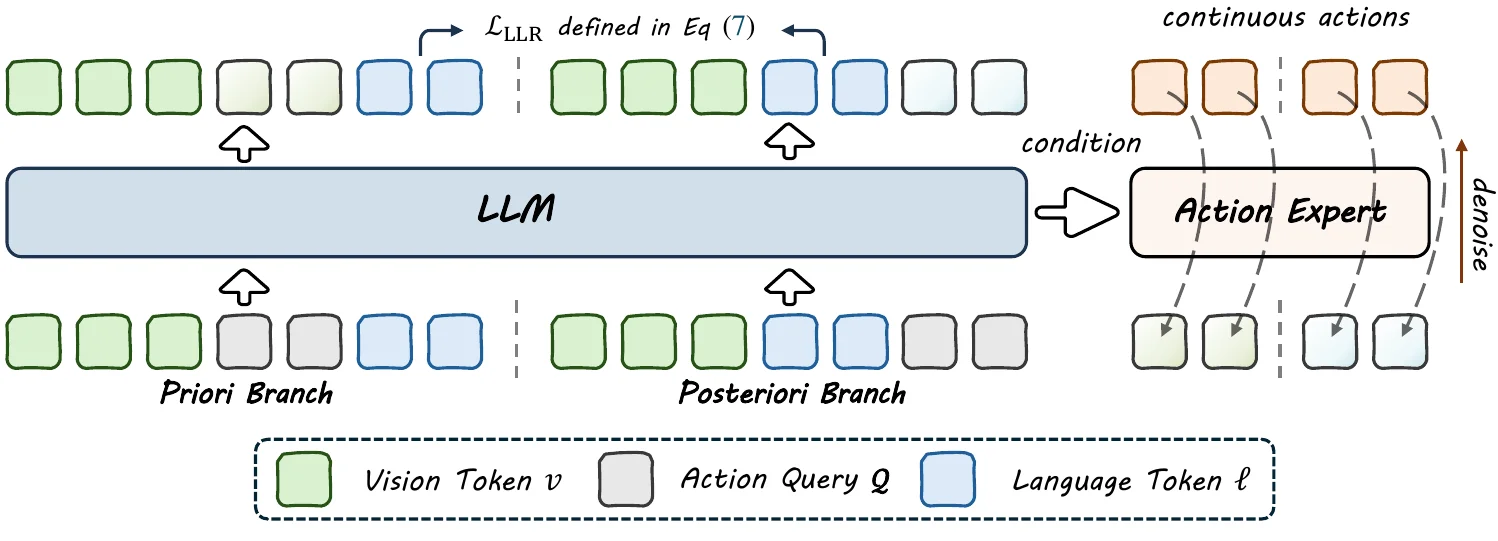
BayesianVLA 貌似重命名为了 Langforce,本身的思路就是有两组的 input,一组是 NTP 的 V+A+L 而另一组是 V+L+A,然后建立两组 L 之间的相似度损失,类似于说让一组主要基于图像,一组则基于语言,从而 force 模型基于语言来建模,后面接 DiT。本身思路其实合理,故事讲得通,中规中矩。
LingBot-VLA#
20K 小时 9 平台双臂数据 + 高效代码库的 Pi-like VLA
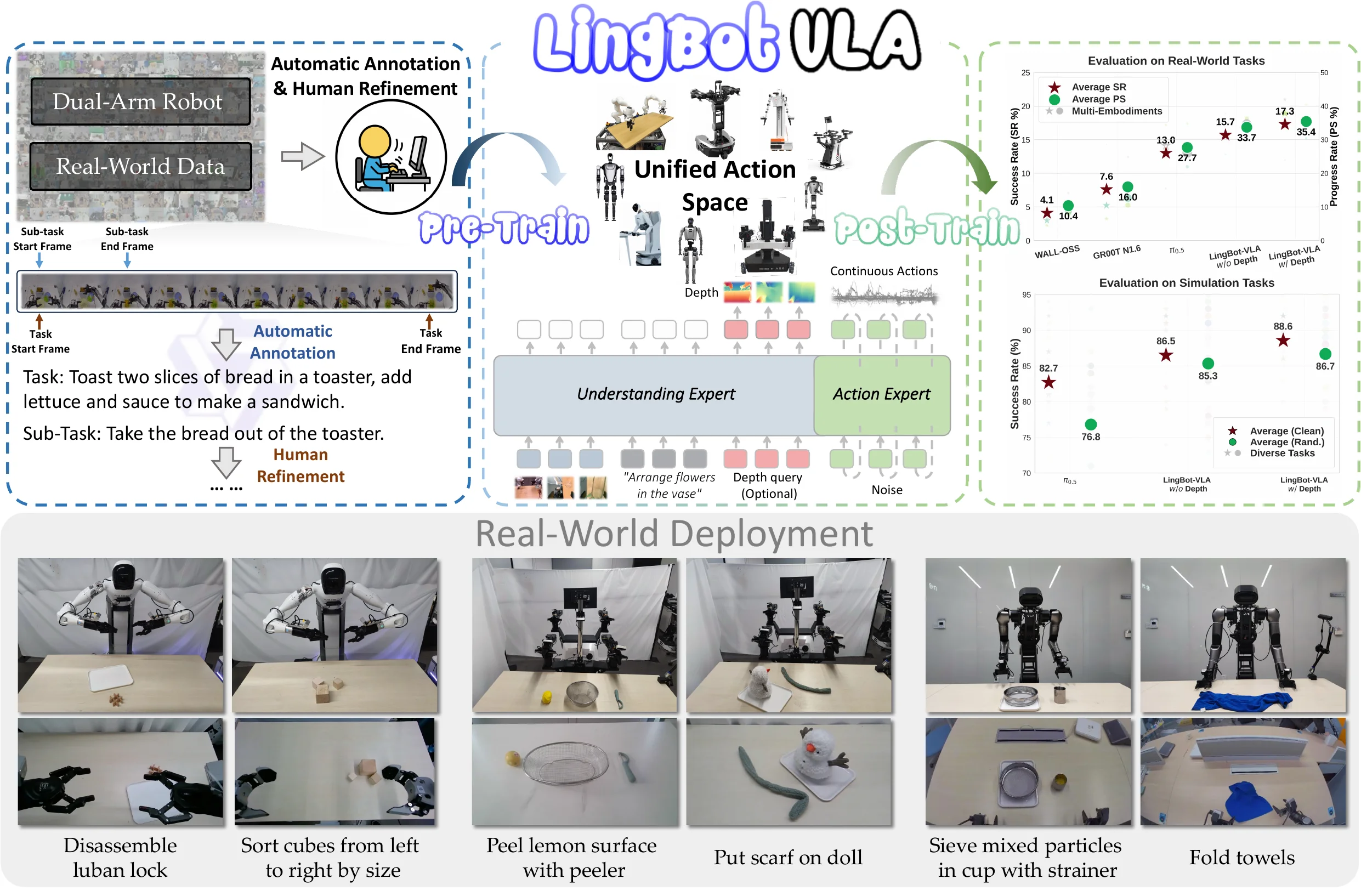
LingBot-VLA 架构上依然是 Qwen2.5-VL + Flow Matching 的 MoT Pi-like 范式,更多是做了 Infra 以及大规模的 Pre-training,其中的 Depth 相关内容更是可有可无。一方面从效率上确实可圈可点,虽然说实际上他们和 starVLA 的比较存在着明显的问题,后面测试下来其实 starVLA 比 Lingbot-VLA 标注的速度要快一些,但是基于 VeOmni 去做 fsdp 也很合理。从大规模数据集预训练之后的效果来看,效果也不错。
Shallow-#
把 Pi-like 的 VLM 与 Action Head 同步蒸到 6 层
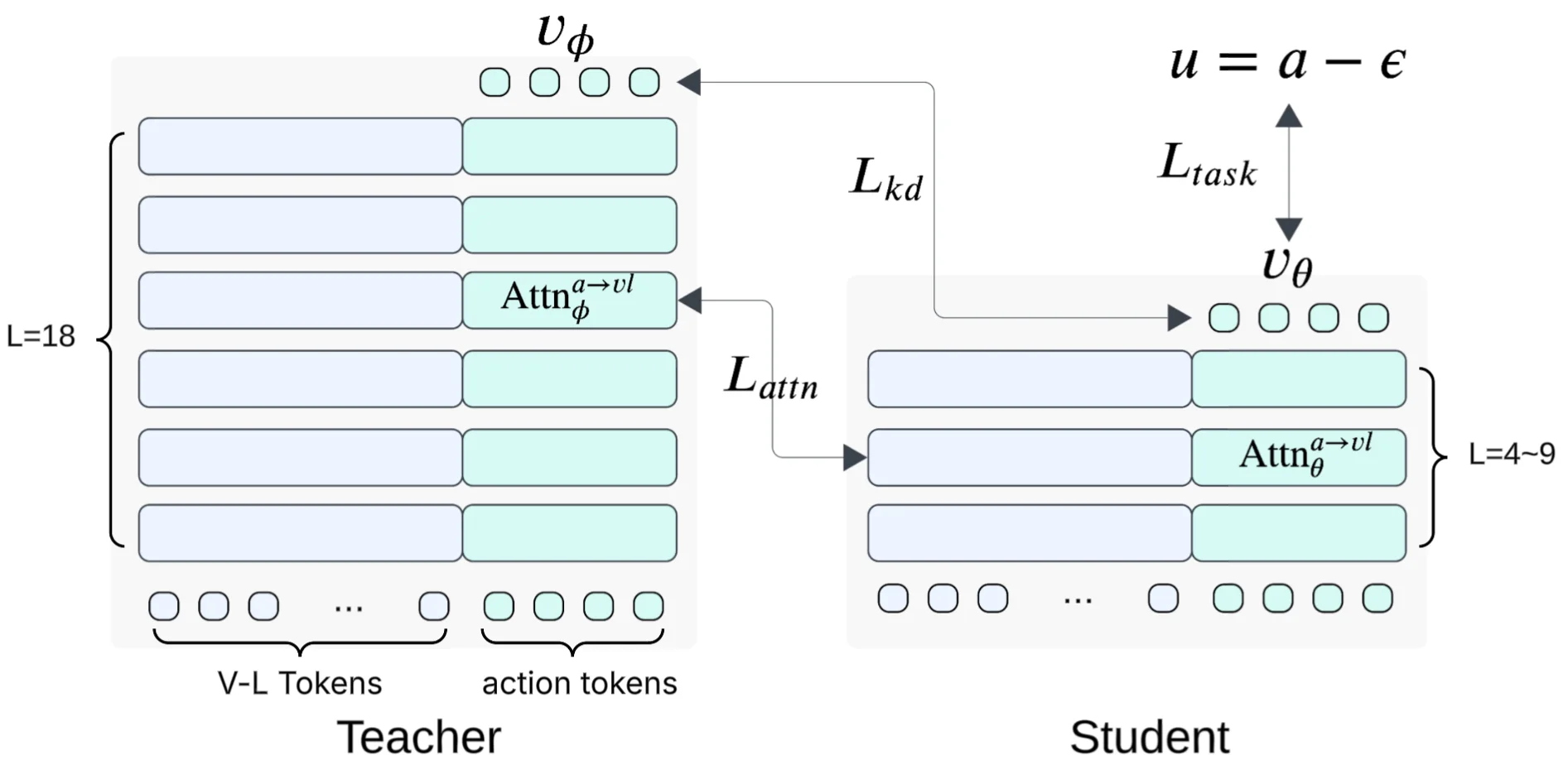
Shallow- 做的就是 Pi-like VLA 的压缩部署:把 VLM Backbone 和 Flow Matching Action Head 都从 18 层蒸到 6 层,Loss 是 task + KD + cross-attention 对齐(只对 action token 的 attention)。工作相对还算干净,没什么问题。
LingBot-VA#
MoT + Causal AR Diffusion 的 Co-training WM-VLA
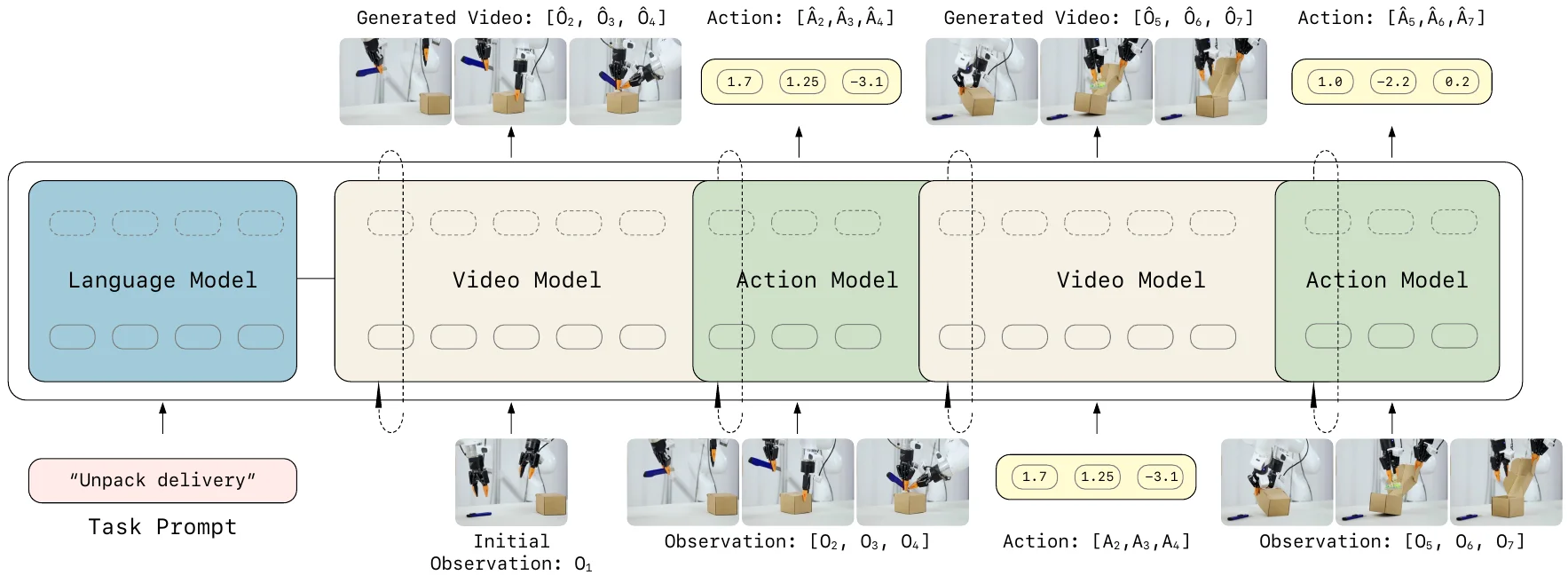
LingBot-VA 提出了一种简洁优雅地 WM-VLA 范式,通过显式的预测 Frame 以及 IDM,在 MoT 中把 video frame 与 action 交替自回归,保持严格 causal 依赖,十分合理。同时,LingBot-VA 利用了 WM 天然的 KV-cache 抗长时序漂移的特性,可以完成本来需要 Memory 的 Long horizon 的任务,非常值得一读。
Green-VLA#
5 阶段课程 + 3000h 数据 + RL 对齐的 Pi-like VLA
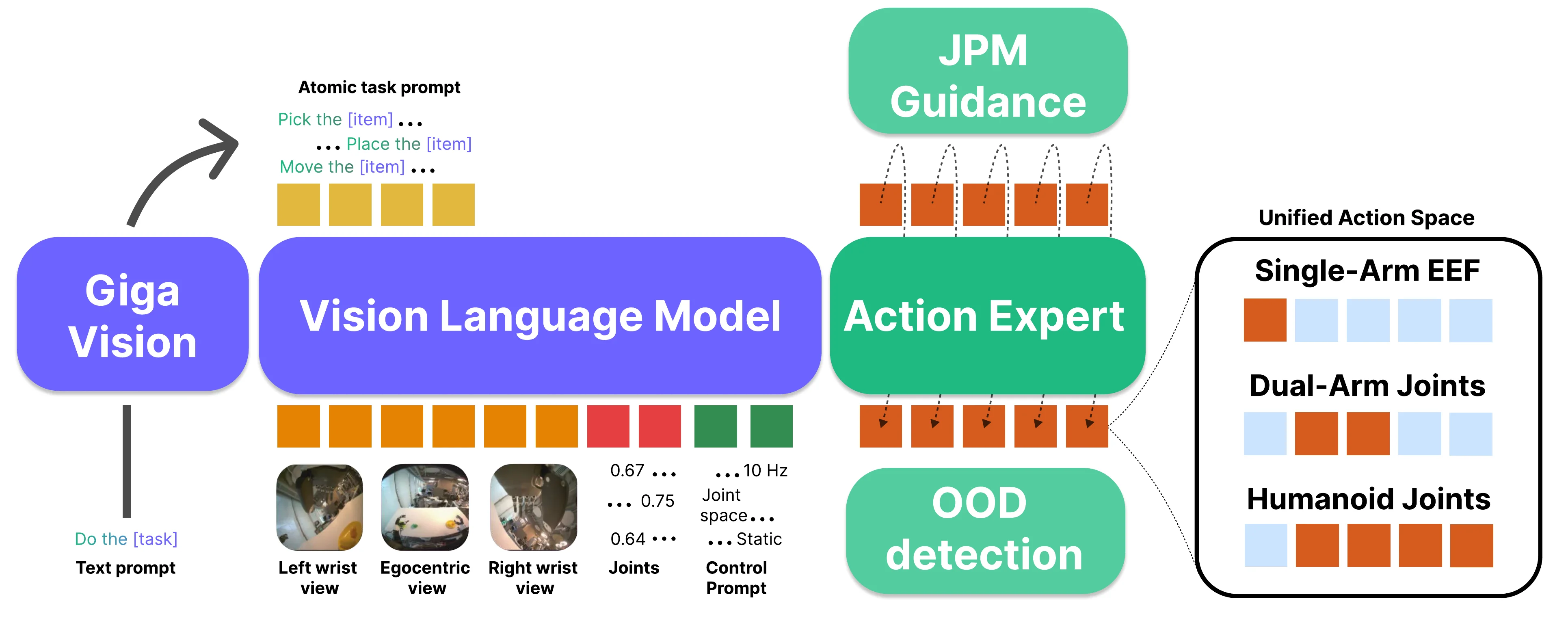
Green-VLA 是一份偏工程的 VLA 全栈,走 L0 VLM → L1 多模态基础 → R0 多 embodiment 预训练 → R1 单 embodiment 适应 → R2 RL 对齐的 5 阶段课程学习,并且使用了 3000 小时数据,最后部署到 Green humanoid 上,本身就是 Pi-like 的模型。本身先使用 GigaChat 做任务分解,L1 就是用 Web 数据训练一个具身大脑的路数,性能并不显著,然后在 R0 的时候用类似 RDT 的 Uni Action Space 来预训练,其中用 DinoV3 特征量化了数据多样性,这个可能还有点价值。之后有一个流引导阶段,流引导也是目前学界比较常见的技术,可以不训练 Diffusion 从而对其造成影响,但是似乎意义没有特别大。最后在 RL 阶段,本身包括了两种 RL:其一,训练了一种 Q 函数,可以对于生成好的 Action 做优化,来优化轨迹,最后把优化完轨迹的数据放到训练集回流;另一个是源分布优化,这里就和主要还是训练了一个 RM,然后有一个小模型根据 Condition 来给出原始的噪声分布,这个做的和 GR-RL 一样,可以直接做 RL。
StreamVLA#
Lock-and-Gated 触发慢思考 + 目标图做时间不变 anchor 的双系统 VLA
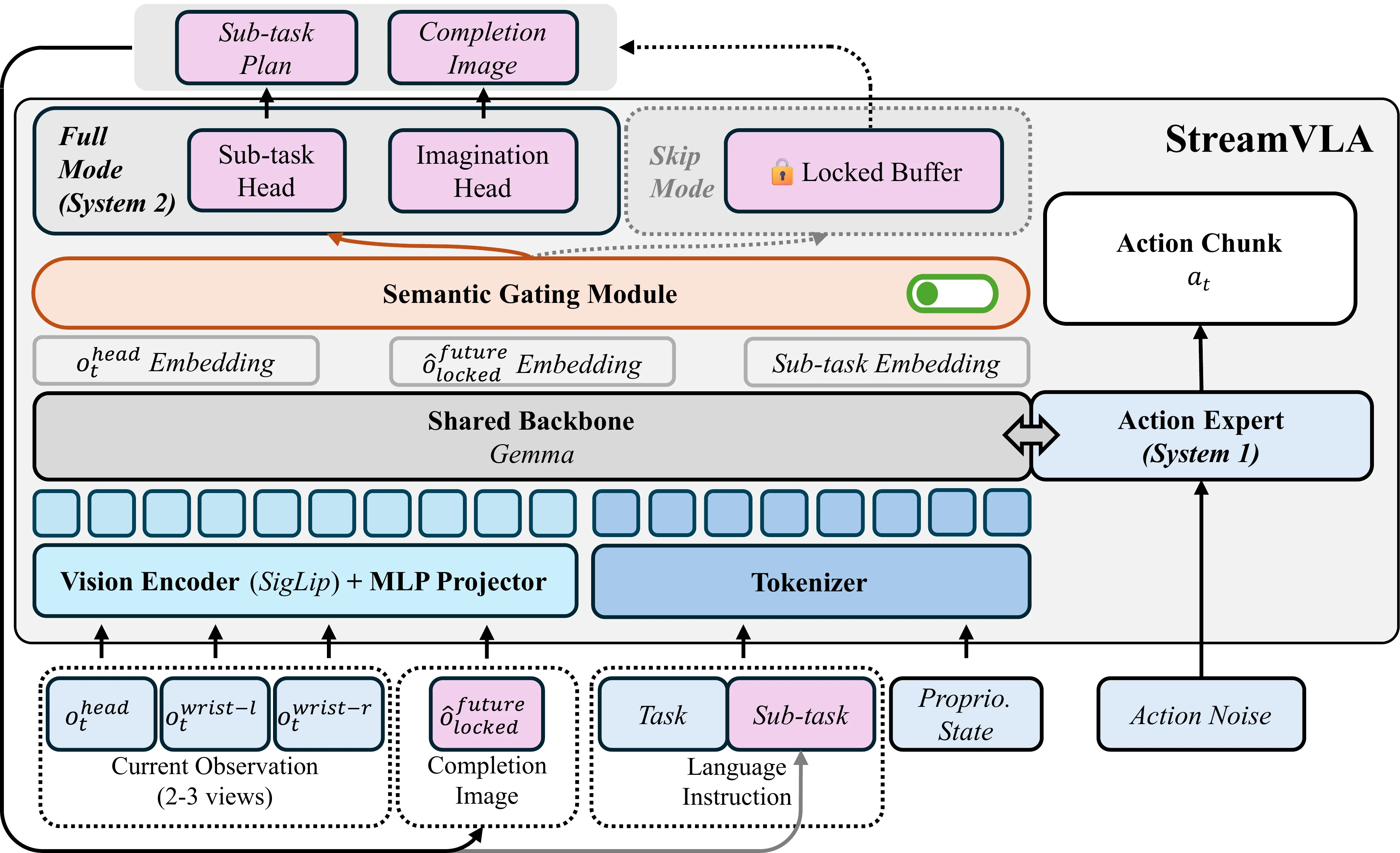
StreamVLA 的核心机制是 Lock-and-Gated:只在检测到 subtask 转换时才触发慢系统生成 text instruction 和 goal image,而这个转换则是以 goal image 和实际的 Obs 的 diff 需要小于一定的阈值,这样子来形成一个闭环,从而可以在大多数时候跳过 system2 的环节,而是只运行 system1。本身模型依然是基于一个 Pi-0.5 like 的 VLA 来做的,作为双系统来说思路还算合理,但是确实假如说 goal image 不是很合理的话,可能也会有问题,不过确实这样子肯定有效率了。
FD-VLA#
从图像 + 状态蒸馏出 force token 的无传感器力感知 VLA
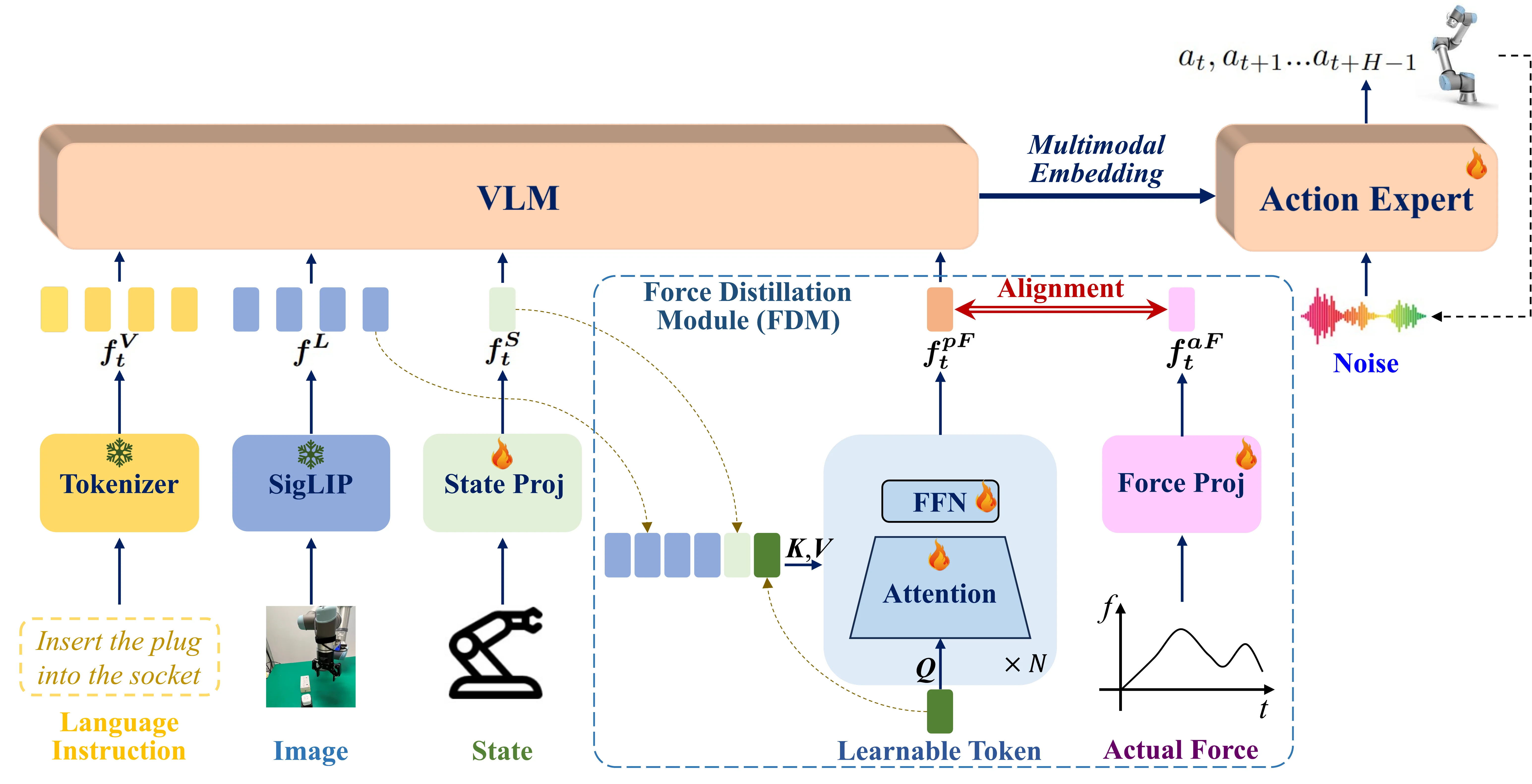
FD-VLA 用一个 learnable query token 以视觉观测和机器人状态为条件去预测力 token,训练期对齐真实 F/T 信号的 latent,推理时不需要力传感器。本身思路也比较好理解,就是用 learnable query 从视觉中来蒸馏出来力的表征,过几层 Transformer 之后就和 Force 来对齐。模型本身还是 Pi-like 的 VLA 模型。比较 counter-intuitive 也比较有意思的结论是:蒸馏出的 force token 性能居然比直接用真实 F/T 测量还好,估计是因为 distilled representation 天然与视觉 / state 对齐,而 raw 力信号在 fusion 时反而带噪。对走 Force-aware VLA 路线的人来说这是一个值得参考的数据点。
RDT2#
7B VLA + 10K 小时 embodiment-agnostic UMI 数据的 Pi-like VLA

RDT2 作为 RDT 系列续作,走的是数据 + Scale 路线:7B 底模,10K+ 小时的 embodiment-agnostic UMI 数据,也算是不错。第一步是首先训练 VLM 模型,本身就是用 RVQ 以及 CNN 将 Action 离散化,然后训练 VLM;第二步冻结 VLM 训练后面的 DiT;最后将 DiT 做了蒸馏,蒸成了单步的生成器。从效果上来说确实速度很快,而且 demo 看上去质量挺好的。
World-VLA-Loop#
VLA 失败 rollout 反哺 WM,再闭环 RL VLA 的互迭代
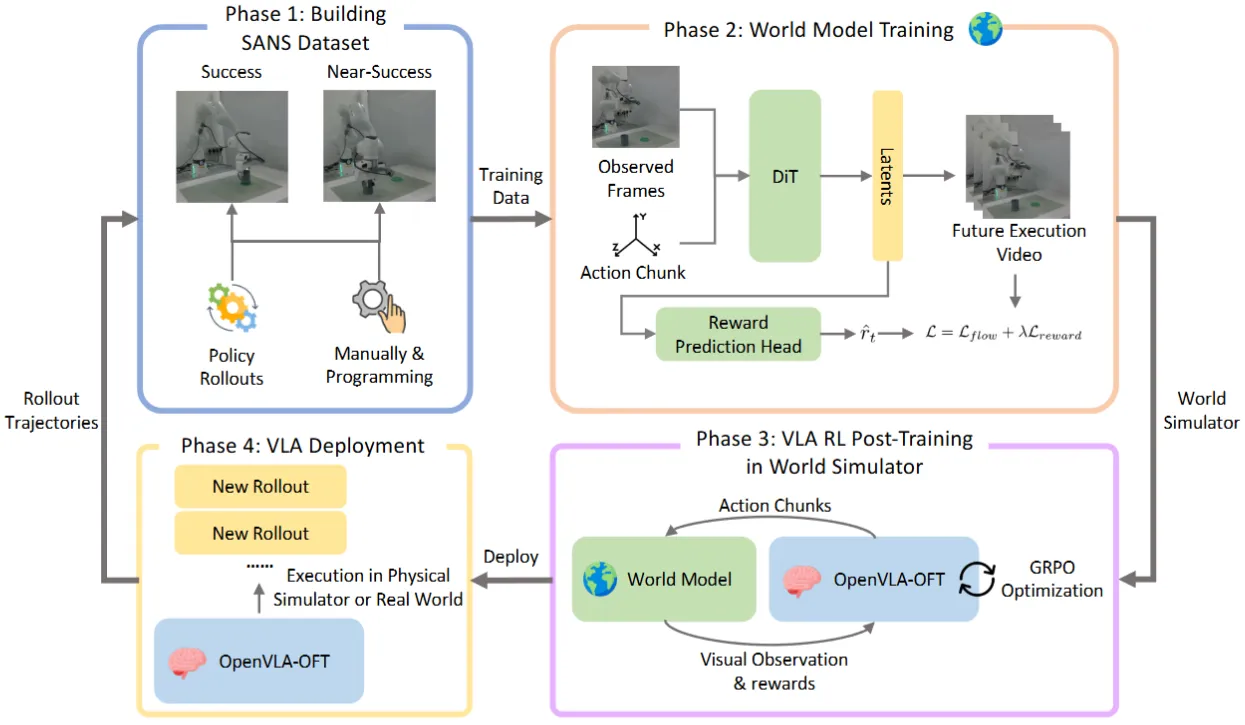
World-VLA-Loop 用 VLA 的 failure rollout 精炼 WM、再让 WM 作为 Simulator 跑 RL 训 VLA,形成互迭代。思路合理,仅靠训练集分布训 WM 有 bias,加入 rollout 可以覆盖更接近推理分布的数据,算是一定程度上解决了本身只用成熟数据集训练训练 WM 可能有的 Bias 问题(这个问题之前讨论过)。然后具体的做法上,本身模型也是 OpenVLA,可以直接上 RL,然后 WM 的 Latents 切出来用一个 Head 来预测 reward,这样 reward 可以是 dense 的(虽然说不一定靠谱就是了),可以直接 GRPO。值得一看。
Humanoid Manipulation Interface#
人形版 UMI
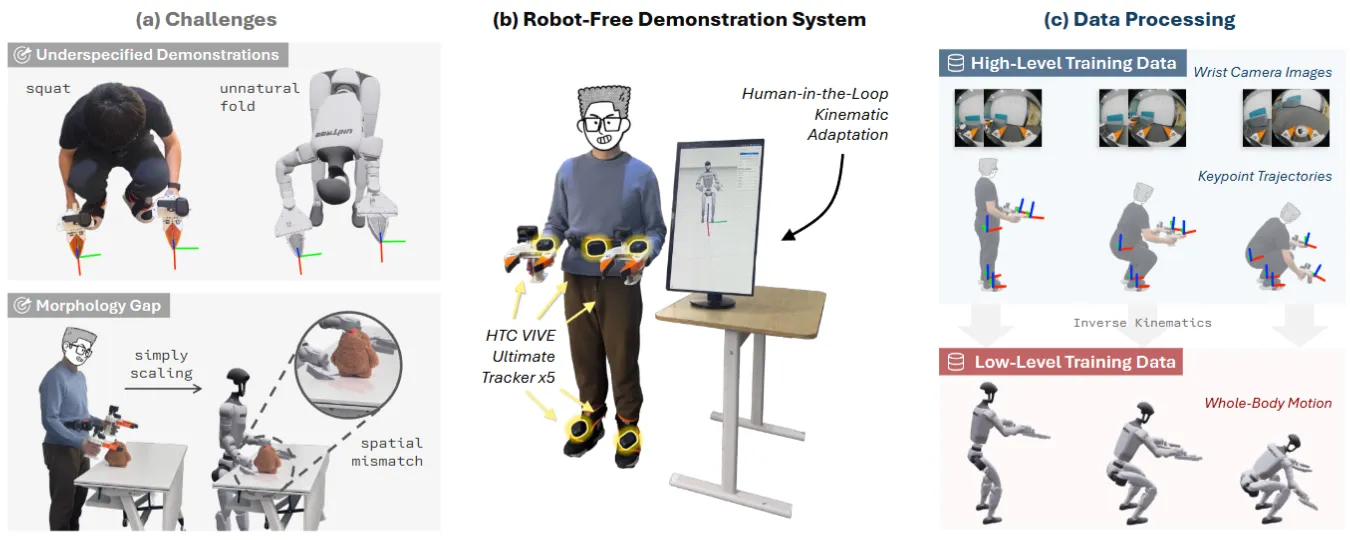
HuMI 就是人形版的 UMI,用便携硬件在没有机器人在场的情况下采集人的全身动作数据,然后通过分层 pipeline 转成人形可执行的技能。不过其实看上去做的比较粗糙,主要还是用 Tracker 以及手柄来采集数据,本身也没有很考虑比如说这个姿态是不是真的机器人可以保持平衡,感觉像是把 VRChat 这边已经成熟的技术直接套过来了,不过看上去在 DP 的训练也算够用,还可以。
DreamDojo#
44K 小时 Ego 视频训出的基础 World Model
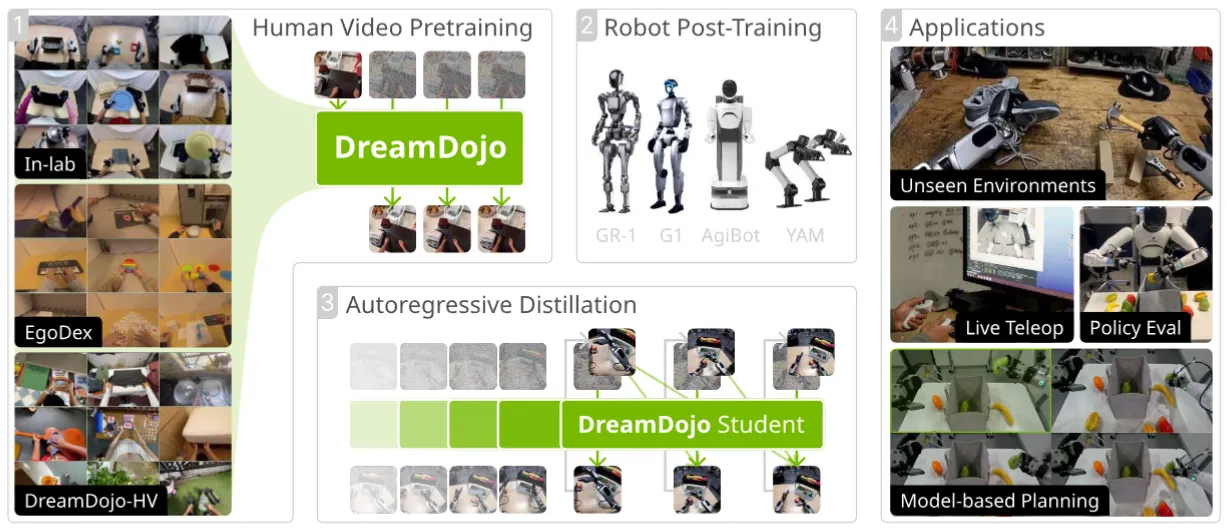
DreamDojo 用 44K 小时 egocentric 视频训一个通用 WM,依然通过类似于 LAPA 的方式来提取 continuous latent action,将这个 action 作为 condition 可以做到一个正常的预训练。如果需要部署到具身,之后在后训练的时候,部署的时候还是直接接一个 MLP 然后预测动作。整体来说是很不错的预训练模型,本身然后模型是一个预训练 WM,VLA 并不是完全的主题。
RLinf-USER#
RLinf 的真机 RL 基建
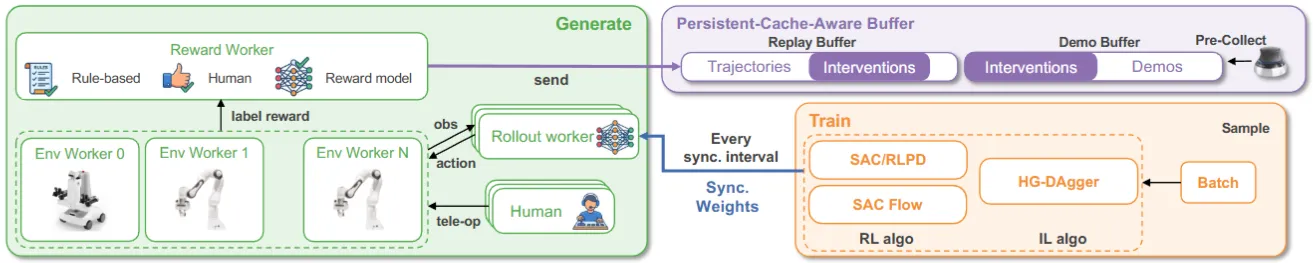
RLinf-USER 是 RLinf 系的新分支,把物理机器人和 GPU 一样当作”一等公民”调度,提供云-边通信、分布式机器人协调、异步训练等基建能力,算是 RLinf 的最新组件,拓展 RL 到了真机 RL,看上去没什么问题,很合理。
BagelVLA#
基于 Bagel 的 MoT VLA
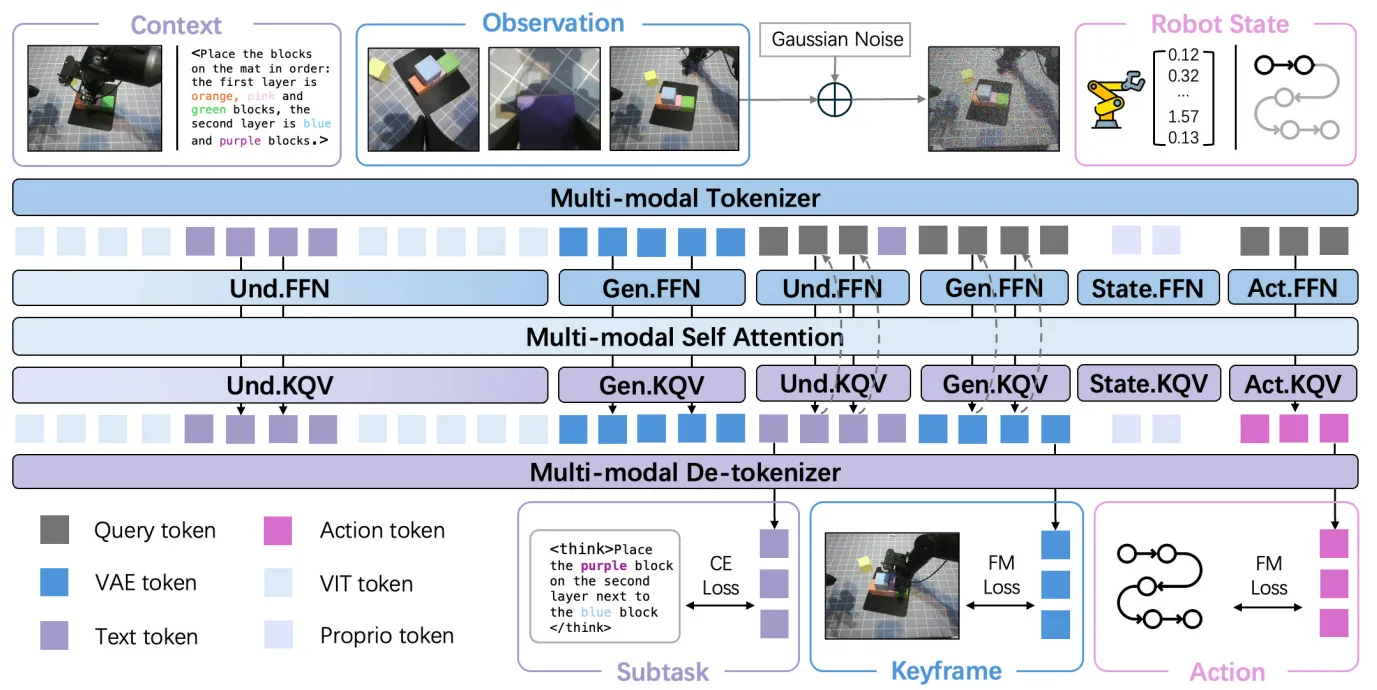
BagelVLA 是基于 Bagel 做的 VLA 的续作,从 Bagel 进行初始化,然后加入了 Actor Expert,以及设计了不同的降噪策略。本身结果上中规中矩,意料之中的 Paper。
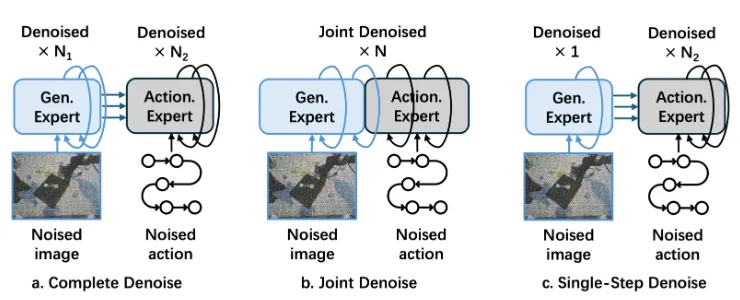
本身比较有意思的是这里比较了不同的降噪策略,分别是,分别降噪,协同降噪,以及让 Image 降噪一步之后开始降噪 Actor,这里面同时对于 Action 的降噪可以从以以前的 Action 为均值的分布来采样,算是一种残差策略。很有意思。
VLA-JEPA#
JEPA 风格的 latent 未来预测预训 VLA
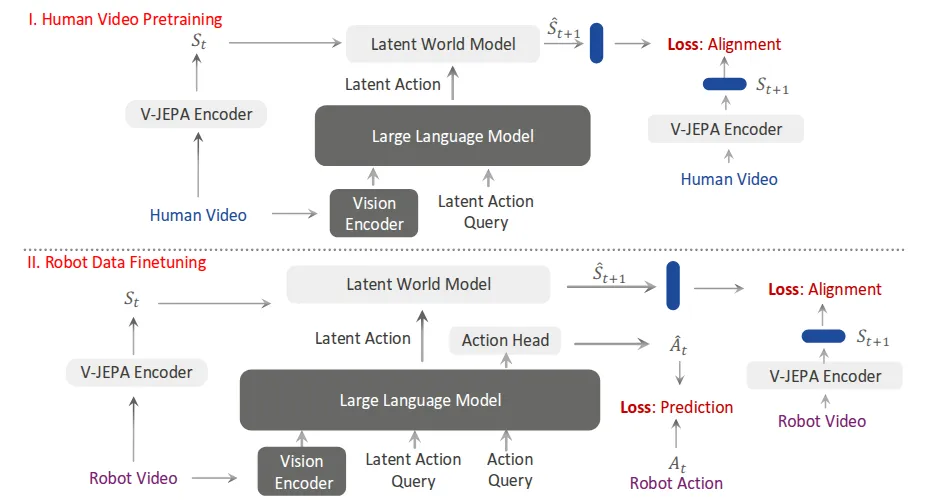
VLA-JEPA 本质上还是为了让结构中的 LLM 来作为 VLA 进行训练,但是在外面接了一个 latent world model,并且用 JEPA 的形式做协同的监督。本身的训练分为两个部分,分别是用人类数据做预训练,以及用机器人数据来做后训练,action 预测还是用 FM Head。整体上的思路感觉问题不是很大,比较合理。
EgoHumanoid#
Ego 视频 + 少量真机,视角 + 动作两向对齐训人形
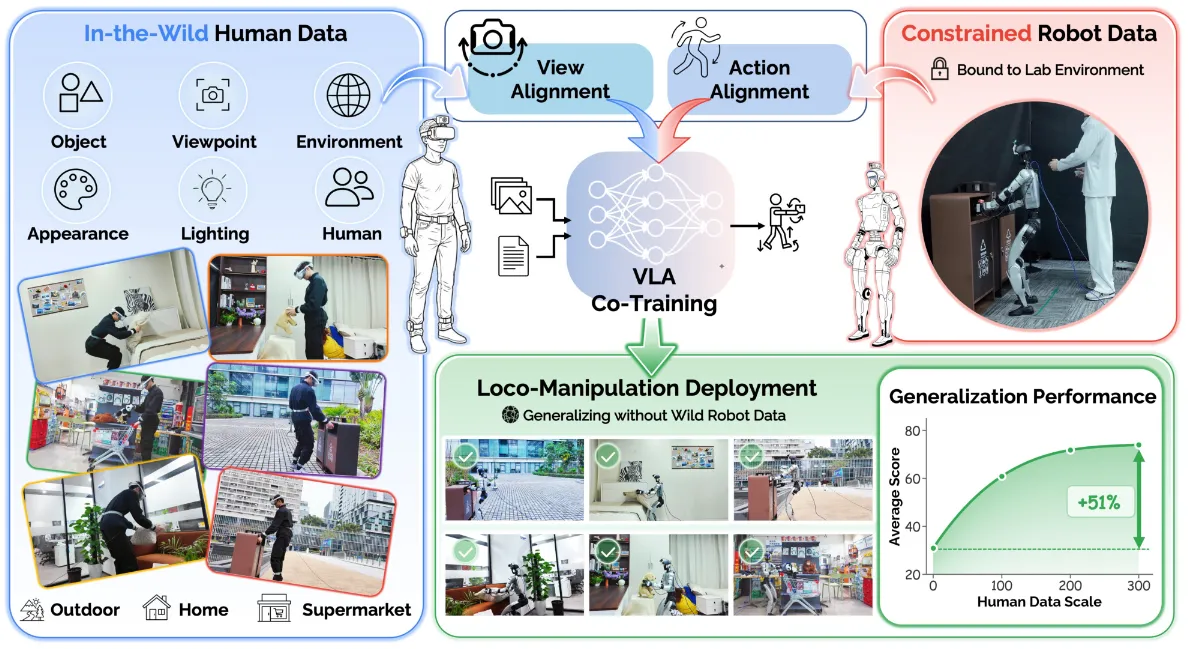
EgoHumanoid 用大量 egocentric 人类数据搭配少量真机数据训人形,关键是两个 alignment:view alignment 处理 head cam 位置不同带来的视觉 domain shift,action alignment 把人类 motion 映射到机器人可执行的控制空间。
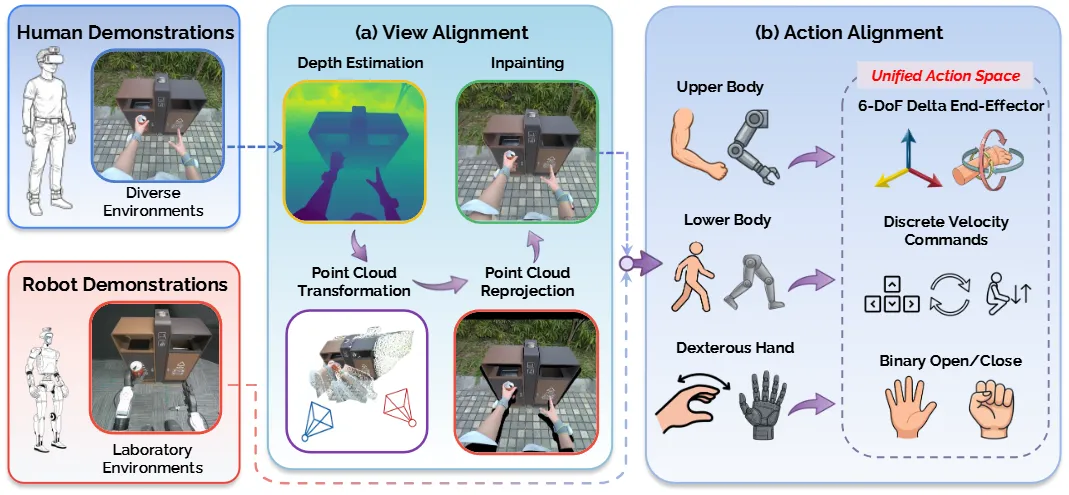
前者主要是通过重新投影估计的深度点并使用生成式修补填充空白区域来完成的,后者就是一个简单的变换。本身模型就是基于 Pi-0.5 进行的微调,下半身控制是离散的指令,所以说不需要很高频的操作,最后可以在 Human+Robot 数据上在 in the wild 来执行任务。
ST4VLA#
空间 grounding 预训 + 空间提示引导动作后训的 Pi-like VLA
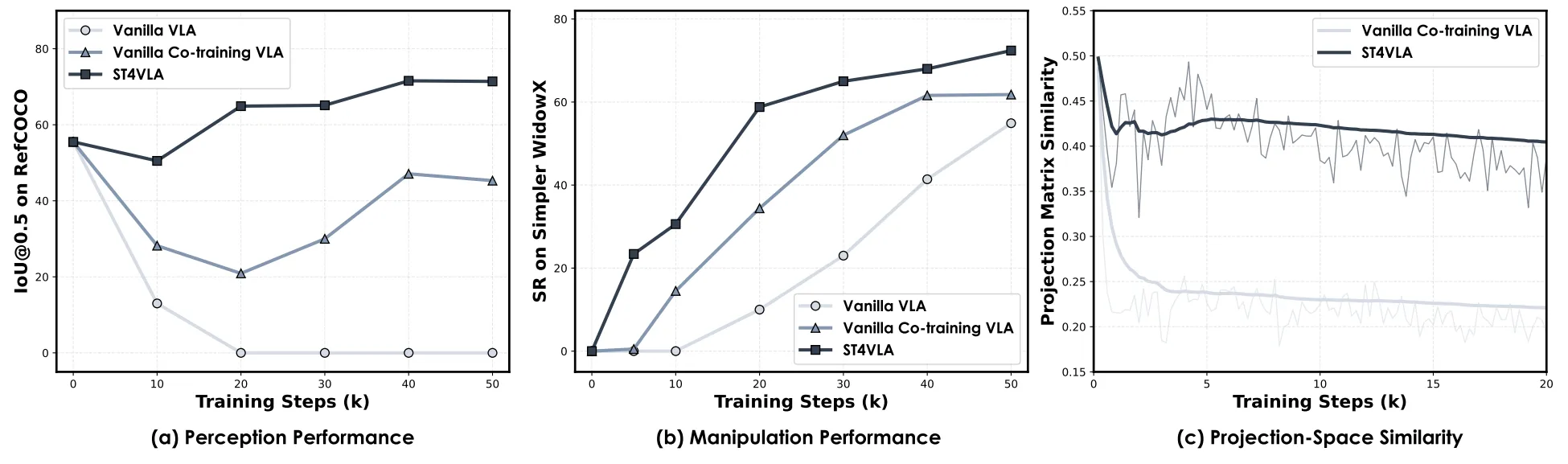
ST4VLA 本质上是 InternVLA-M1 的学术版本,并且中稿了 ICLR。讲述的内容其实和之前的技术报告差不多,但是在里面又探讨了对于 co-train 的时候带来的协同监督在 VLA 训练伤对收敛以及优化在内的东西的考量,以及我们的协同监督的训练形式的优胜,在一定层面讨论协同训练的有效性。
LAP#
语言描述的动作 + Pi05-KI 的 Pi-like VLA
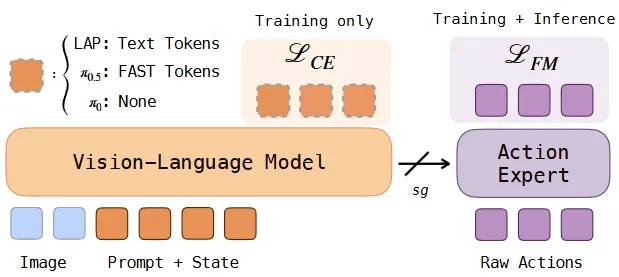
LAP 本身从形式上很接近 Pi05-KI,甚至本身在网络结构中也类比了 Pi05-KI,这里的区别就只在于,LAP 本身使用了他们定义的 Language-Action,也就是所谓的 LA。LA 就是用语言描述的 EEF 动作,比如说向前移动 3cm 这种,从而可以使得 VLM 更好地学习,这从思路上和之前的 VLA-0 是比较类似的,之后依然是 KI + FM Head 直接训练,可以在现实世界的一些任务上泛化,但是也并不显著,看上去没啥问题。
Vista-WM#
WM 生成 subgoal image 指导 VLA 执行的分层框架
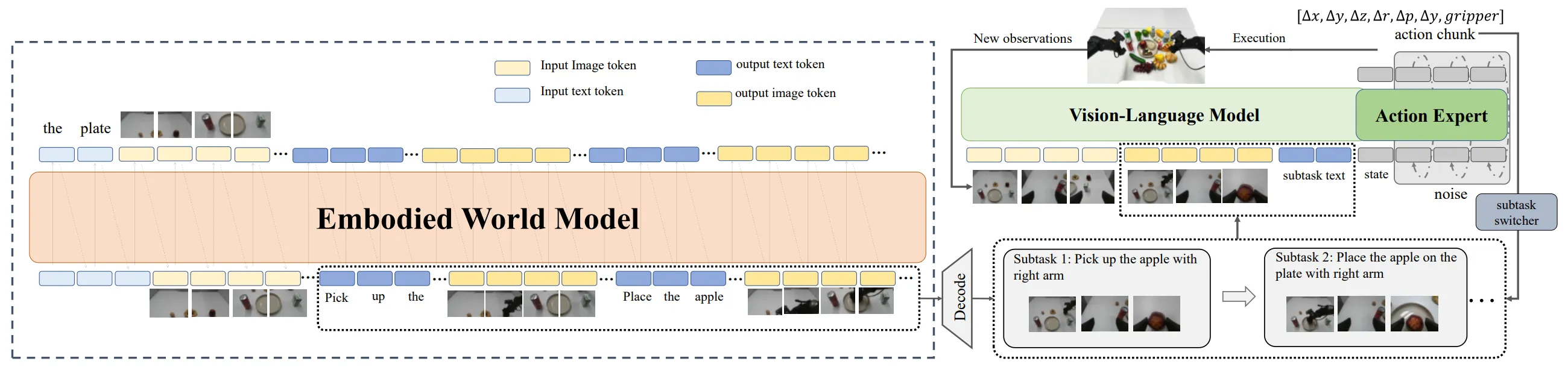
Vista-WM 让大 WM 先把任务分解成一串 subgoal image 再交给 VLA 执行。说起来这种类型的工作在很久之前就已经被诸如 SuSIE 这种类型的工作已经占坑了,大概就是”WM 想象 subgoal image”路线。从本质上我可能不会足够看好这种思路,所谓 WAM 或者 WM-VLA 可能是一个不错的 system1,但是明显如今 WM 还没有 reasoning 和 planning 的能力,接收的信息也有限,作为 system2 可能不足够合理。
BeyondMimic#
人类 demo + Latent Diffusion + Classifier Guidance 的人形技能组合
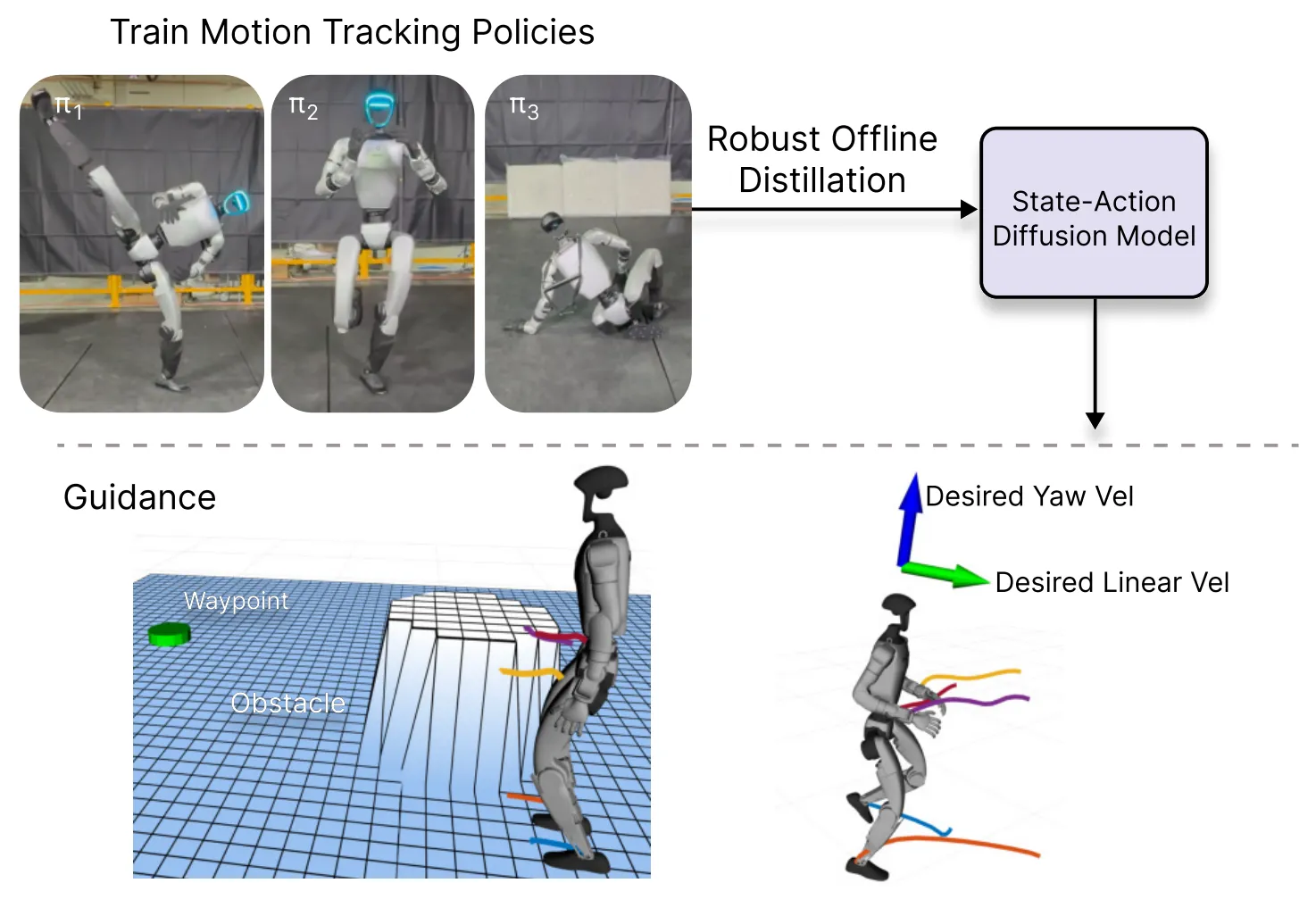
BeyondMimic 是在一段时间的 LocoMotion 发展之后做的比较出色的代表工作之一。本身的方法其实还是和之前的一系列内容比较类似,里面有一些细节不在这里赘述,大概还是用紧凑的 motion-tracking 先把一堆高动态技能学下来,再用 latent diffusion + classifier guidance 做技能组合和 unseen 任务泛化,支持 motion editing、teleop、避障,零样本部署到真机。如果是相关方向的读者,值得一读。
SONIC#
42M 参数 + 100M 动捕帧的人形 Motion Tracking 基础模型
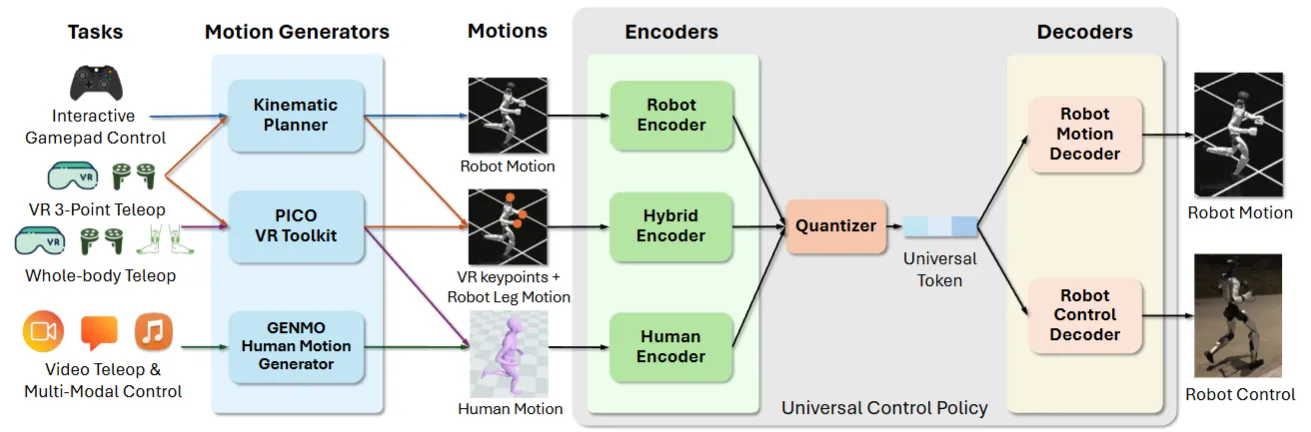
SONIC 把 Humanoid motion tracking 按 Scaling 思路往上拉到 42M 参数 / 1 亿动捕帧量级,通过统一 token space 支持 VR 遥操作、人类视频、VLA 等多种输入。可以看成 Humanoid WBC 的基础模型侧尝试,非常的 Solid,看上去效果也非常好。
HoloBrain-0#
把相机参数与 URDF 作为 embodiment prior 注入的 VLA
HoloBrain-0 本身算是团队 Tech Leader 使用地平线的资源给自己的之前的工作 Sem 做的后续工作。因为 Sem 之前没有进行介绍,所以在这里简要介绍一下。
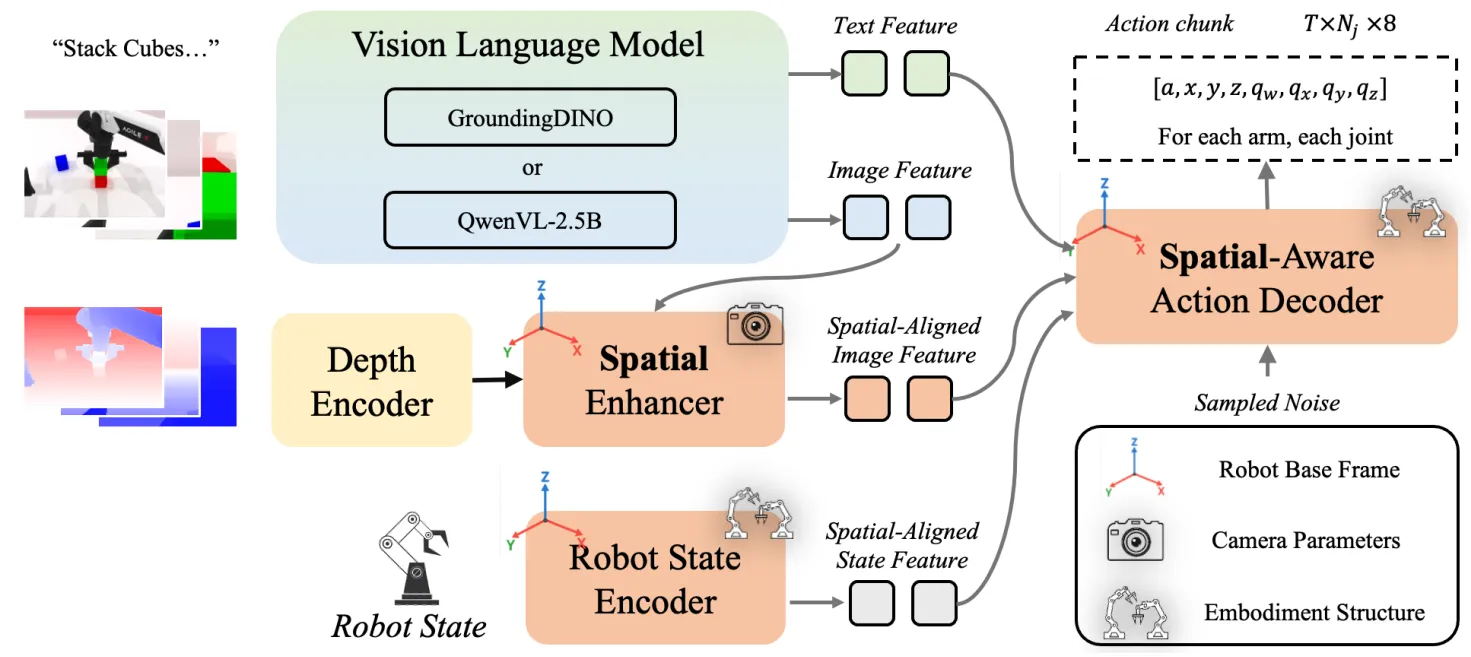
可以看到 Sem 本身就是 VLM + Depth Encoder + Action DiT 的组合,然后对于 Action DiT 里面加入 Joint Graph Attention 来根据 URDF 硬编码一种计算模式。本身可以看到 HoloBrain-0 的做法几乎是一致的,但是在更多的数据上进行了预训练,其中依然使用 DINO 或者 Qwen 作为基模,然后还是所谓的 Unify Action Space,其实就是 EEF。
本身显式进行编码显然并不 Bitter Lesson,从我的角度来说感觉存在一些 Limitation,从这个角度说利用了本体的先验似乎是 make sense,但是其实我并不认为这种先验的意义很大,模型本身不应该从不同的本体上学习到一种模式切换,而是应该在一个模式下进行学习,从而学习出来一种共同的直觉。从结果上来说性能还是不错的,还可以。
LDA-1B#
在 DINO 潜空间里联合预测动力学 / 策略 / 视觉的 1B 基模
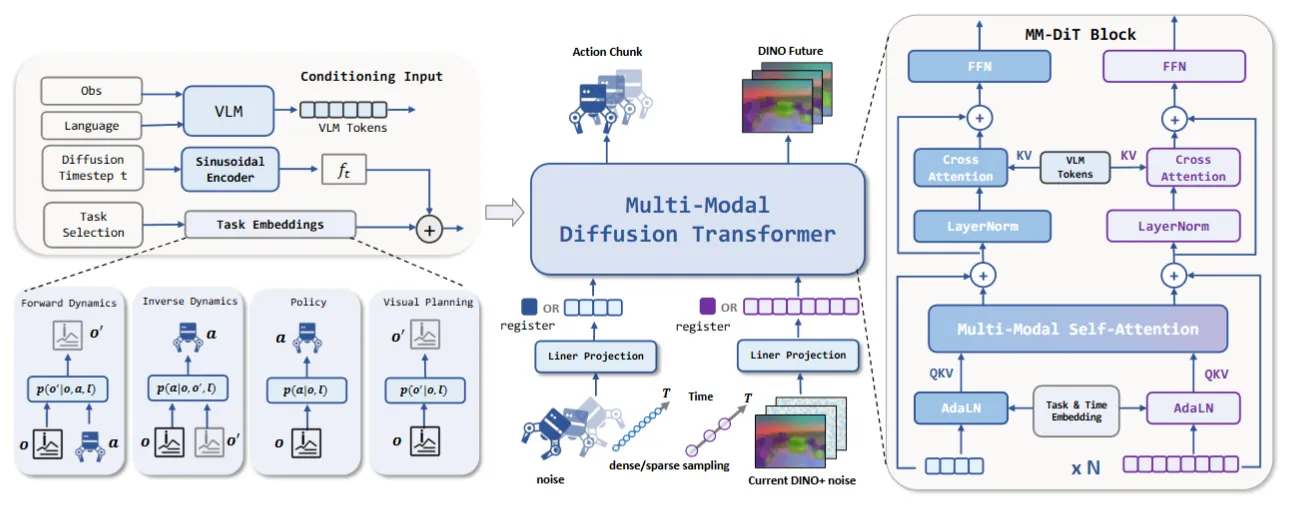
LDA-1B 是 1B 参数的 foundation model,在 DINO 的 latent 空间联合训 dynamics、policy、visual forecasting,异步视觉 / 动作流由 MM-DiT 处理。也就是说使用 MM-DiT 来输入 Action Noise 和 DINO Feature 来预测未来的 Action 以及 DINO Feature,然后同时因为任务选取的不一样,包括说 VL condition 以及比如说某些 Task 需要的额外输入,都用 condition 在处理之后加进来。算是比较 Scaling 来训练一个 Latent 基模,还算有趣。
RLinf-Co#
SFT 混合数据 + Sim RL + 真机辅助监督防遗忘
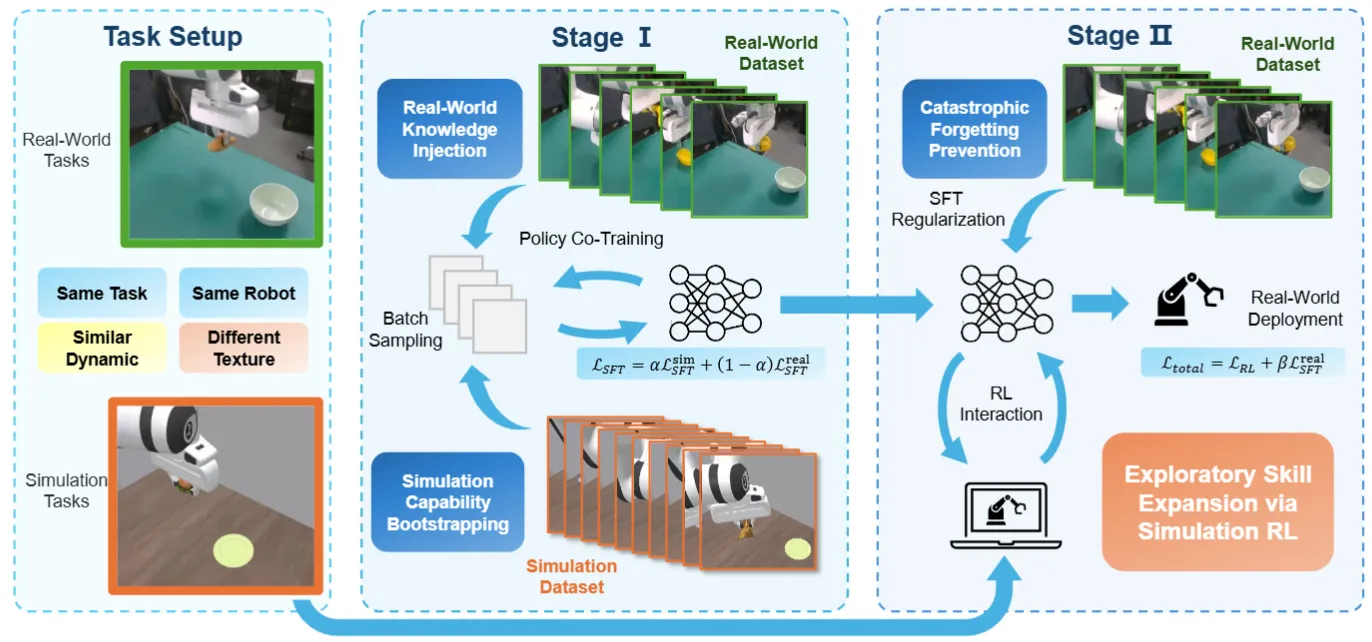
RLinf-Co 还是基于 RLinf 这个比较不错的 RL Infra 来进行的探索,从 RLinf 生态的角度来说,其实是在强调其框架可以做 SFT co-training 这个点。本身也是两阶段,先在仿真 + 真机混合 demo 上 SFT 暖启动,再在仿真里做 RL,同时用辅助 supervised loss 保留真机能力。结果上肯定是效果变好了,而且因为不需要真机的 RL,所以说效率快了不少,是值得参考的内容。
Xiaomi-Robotics-0#
小米的 VLA 基模,三阶段训练
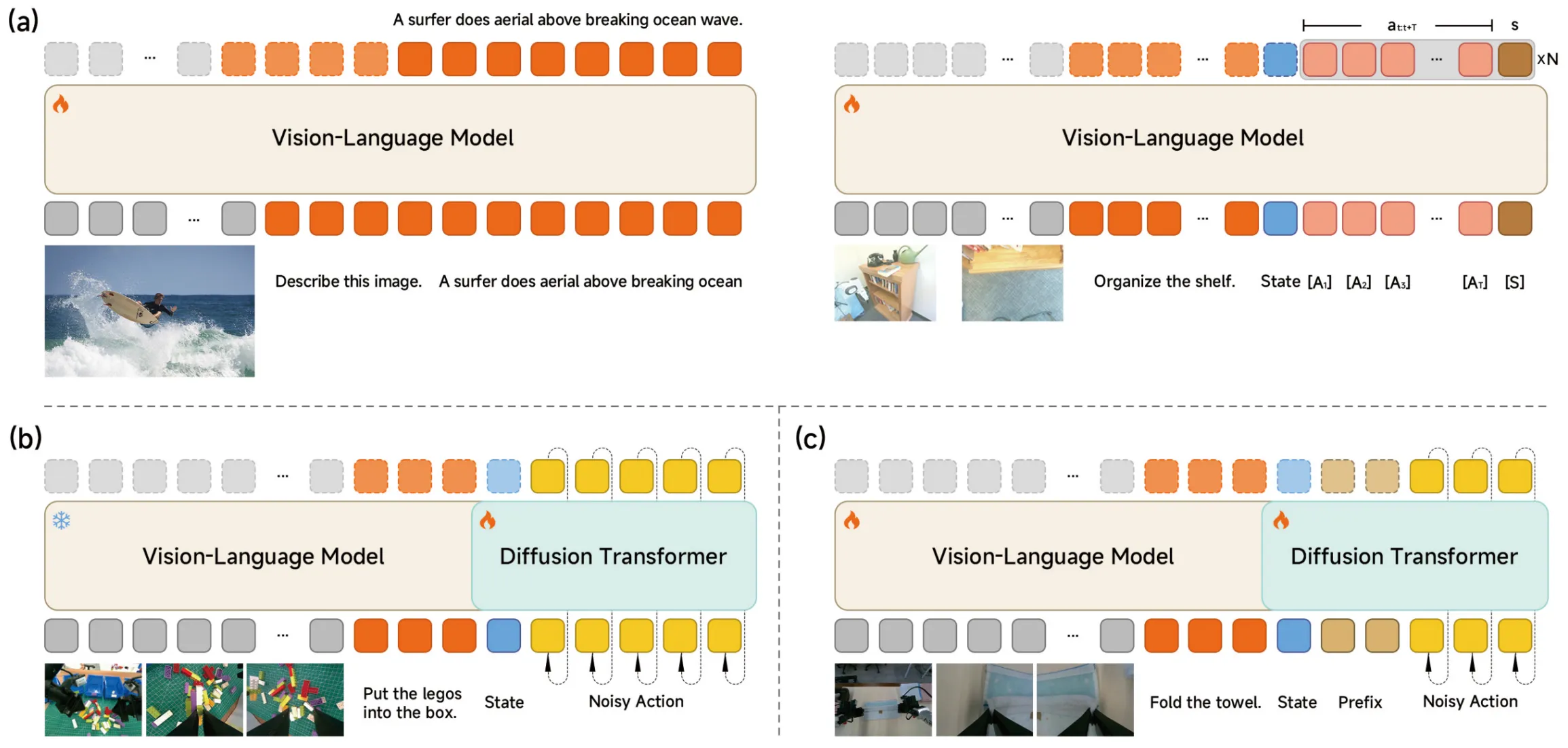
Xiaomi-Robotics-0 本身是小米做的基模 VLA 模型,还是使用了相当多的工程优化手段来从第一性解决问题。本身的训练如图中所示,其实分为三个阶段。第一阶段正常的进行 VLM 的预训练,这里面同样也使用了机器人数据,但是使用了他们引用了一篇叫做 choice policy 的论文的方法来去使得直接 VLM 的 action token 预测也可以建模多峰分布,原理其实也比较简单,其实就是同时输出一个 score,然后最后选择 score 最高的来作为动作建模;第二阶段就是正常的把 VLM 冻住,然后去训练 DiT;之后第三阶段则是为了异步推理做了一些适配,主要使用了 training RTC。最后从效果上来说,觉得还算中规中矩,还是很不错的。