
Paper Reading: Embodied AI 6
从一些 Embodied AI 相关工作中扫过。
VLA-RFT#
使用 WM 作为 Simulator 进行 Rollout 并且用 GRPO 进行强化学习的 Workflow
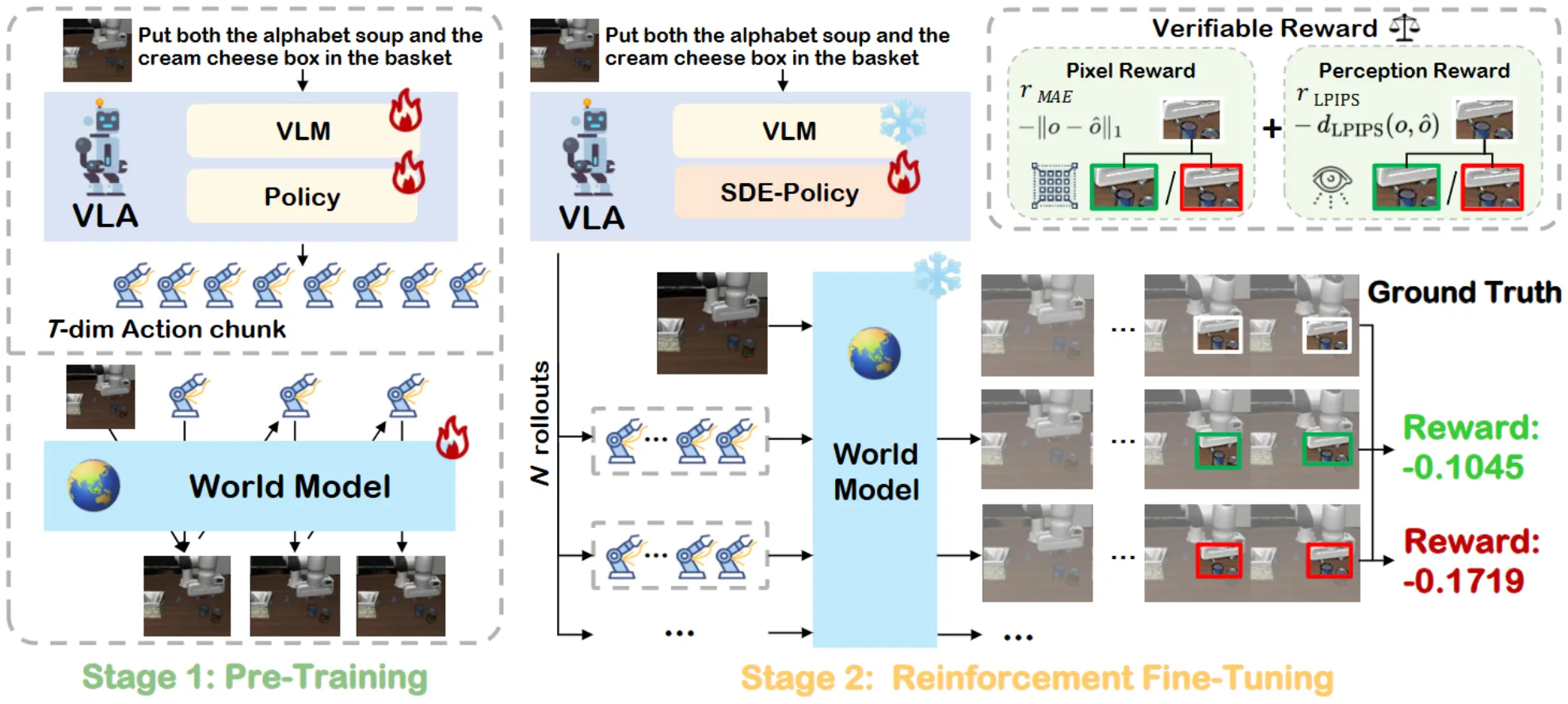
VLA-RFT 的思路如图中所示,其实相当直观,在预训练了 WM 以及 VLA 之后,将 WM 作为 Simulator 来 rollout 一些 RL 的样本。一切当下使用 WM 作为 Simulator 的范式都没有解决根本问题,即 WM 的并不高保真,所以可以看到本身论文给的 Sample 依然是从 Libero 里面学出来的。本身的 Reward 感觉也有点奇怪,似乎是根据画面而非更加语义的内容进行的推断。
ContextVLA#
给现有 VLA 模型添加 history 信息输入
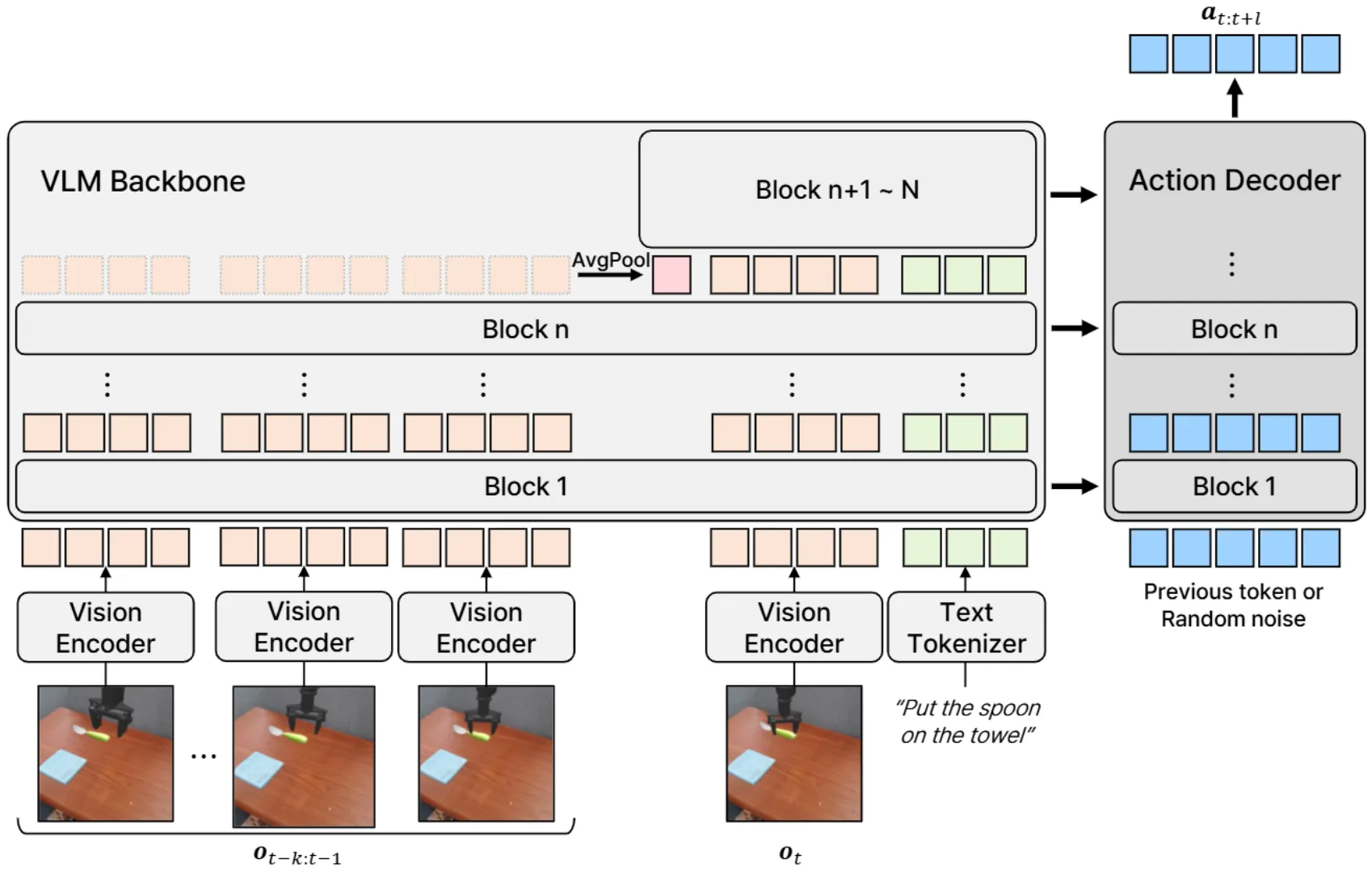
ContextVLA 其实讨论了一个比较远古的话题,也就是直接为 VLA 添加历史信息,这种方法显然是有效的,但是 ContextVLA 似乎没有给出一些有意思的实验。History 的选择其实一直以来都是领域的一个问题,类似的,导航领域中其实已经给出过很多对于 Memory 进行管理的方式,类似于储存最不相似的 frame 并且 pop 最相似的,而不是直接使用 history,因此看上去 novelty 一般。同时,我其实比较期待 ContextVLA 可以给出一些需要 Memory 才可以进行的任务的 Case,但是似乎只是一些可以用第三视角相机就可以解决的任务。对于具身,感觉在 Task Demo 的设计上有参考价值也是不错的。
VLA-R1#
使用 R1 训练具身 VLM
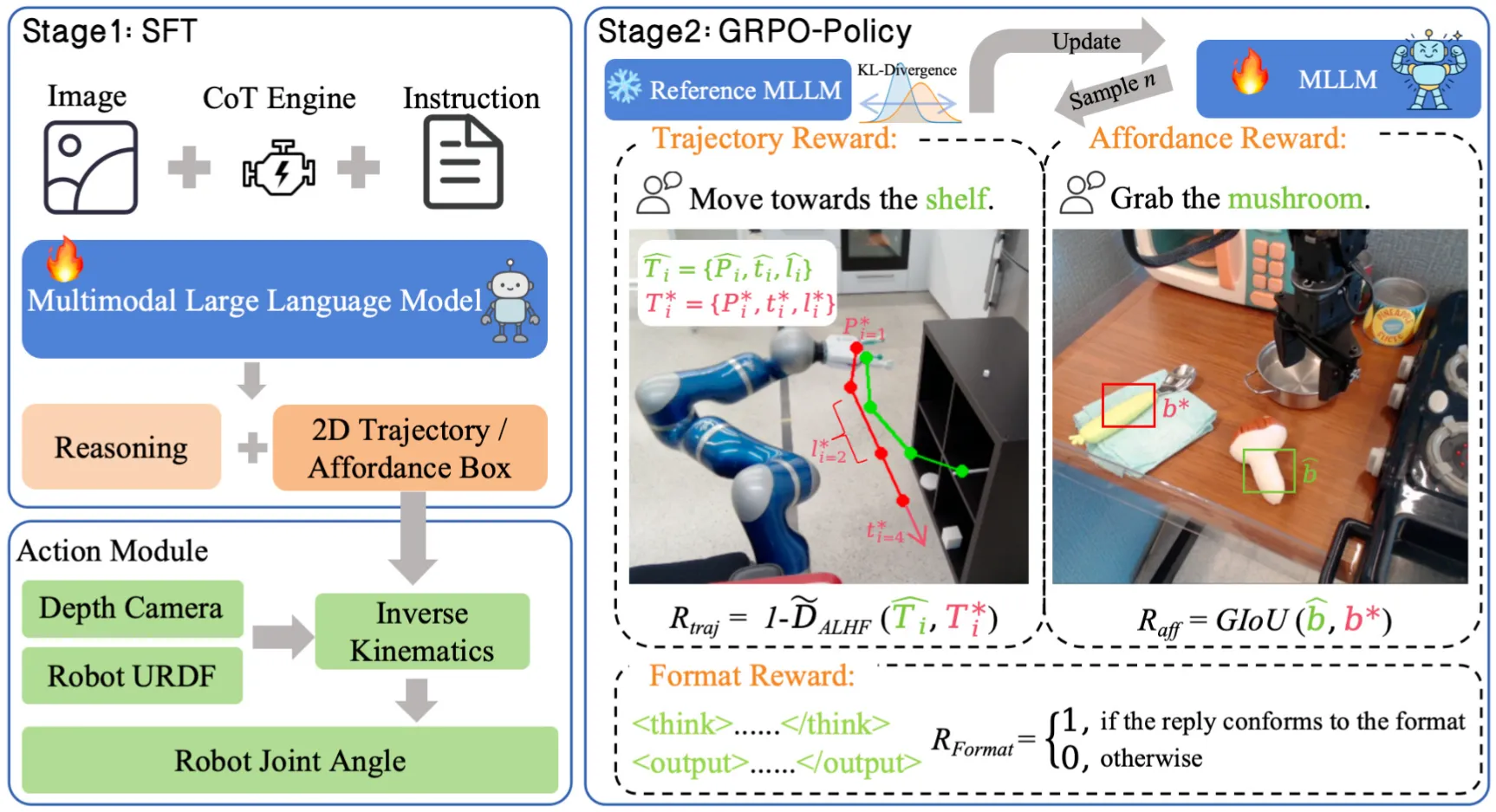
VLA-R1 十分直观,就是制作了一些 CoT 的数据,然后用 GRPO 来训练一个 VLM。类似的 Topic 别人已经做过很多了。
Best of Sim and Real#
提出两阶段学习,先在仿真中学,之后 Bridge 到 Real
Best of Sim and Real 其实进行了一些比较有趣的讨论。因为众所周知的原因,仿真中存在大量的特权信息(也就是现实中正常获取不到的,比如说 GT 的 Semantic Mask,每一个物体的精确的 Mesh),所以非常适合让模型在里面进行学习(只要仿真可以仿出来)。这篇论文本质上探讨了,要是我们希望使用仿真训练模型,应该如何去做,本身可以理解为在仿真中 explore action space,之后在现实数据上解决一下 visual gap。
当然事实上这种先验似乎是显然的,同时更加重要的启发可能还是在于如何在仿真中,如果使用强化学习,解决 dense reward 问题;如果生成数据,生成的仿真数据的 Gap 在哪里。文章在有限的内容中进行了探讨,还算是有启发性,更多细节见原文,比如说提出的视觉桥接器。
NOTVLA#
预测稀疏化轨迹的 VLM
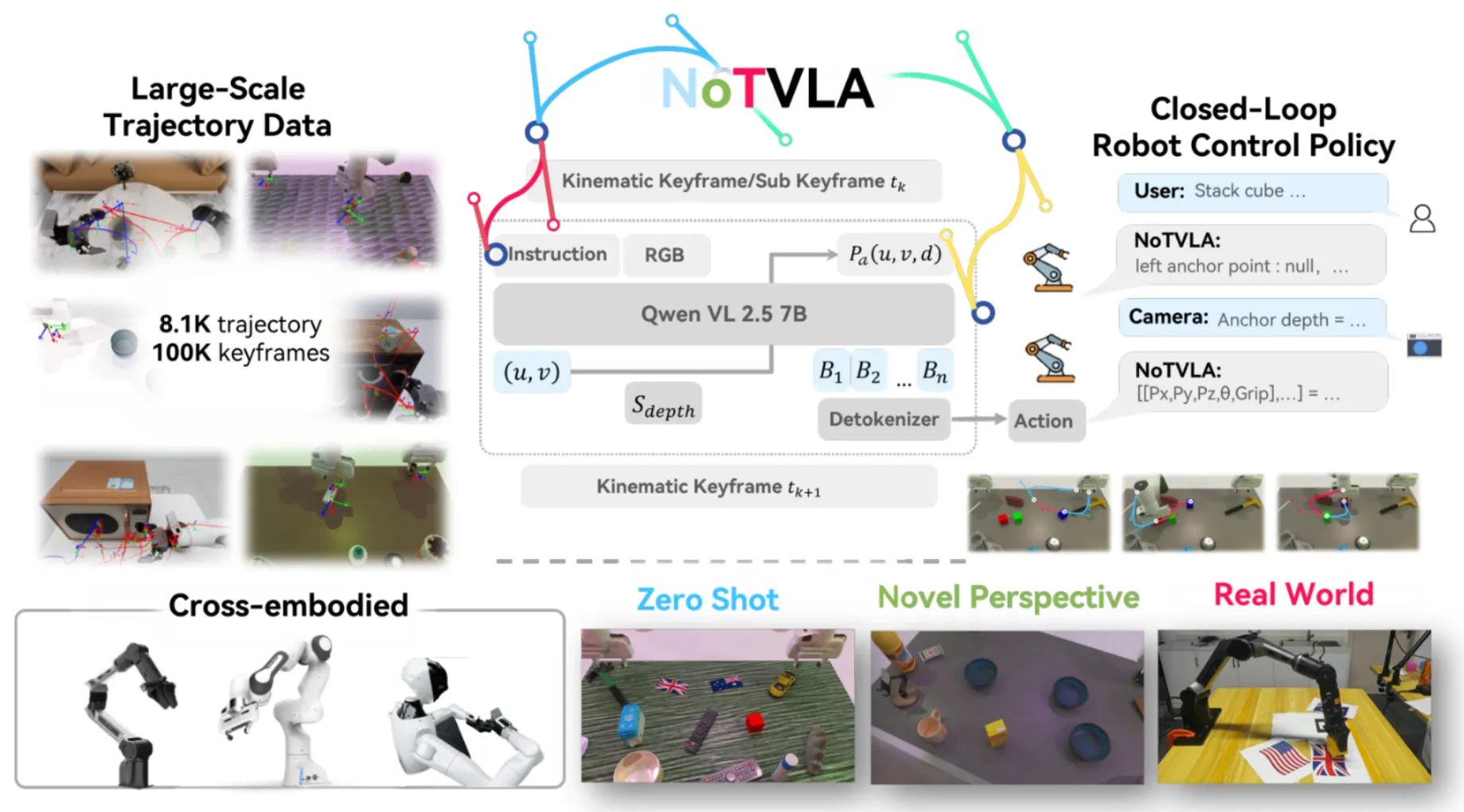
NOTVLA 本身的 Motivation 其实类似于某一种对于 Motion Planning 的 Hack,也就是我们可以通过 Key Pose 来进行轨迹规划来得到完整的轨迹。这从本质上是说得通的,Key Pose 确实足以表征很多的信息,但是其实本身依然不好学。NOTVLA 本身使用 Qwen 作为基模,定义了 anchor 以及 ACTG 作为中间表征,从而可以更好地让模型输出(而不是直接在六自由度下进行预测),这也是之前的工作比如说 PIVOT 试图解决的。模型在 RoboTwin 以及 AgiBot 的挑战赛中进行了实验,获得了不错的性能。当然,Limitation 依然明显,似乎这种方法不能处理灵巧操作以及类似的需要涉及连续连贯操作的任务。
FlowVLA#
引入光流作为额外监督的 WM-VLA

FlowVLA 基于 Emu3 进行了两阶段训练。在预训练阶段,如左图所示,FlowVLA 主要引入了光流的图像并且进行交替的预测图像以及光流,这其中图像在 VLM 的输出通过 VQ-GAN 编码后 Token 的形式。这种额外监督可以让模型更好地学习到视频中的动态信息。之后,在第二阶段,模型直接在下游任务上微调,并且预测 Action Token。从架构上来说,可以理解为将 Emu3 作为 OpenVLA-like 的模型结构。本身中规中矩的论文。
RLinf-VLA#
仿真强化学习框架
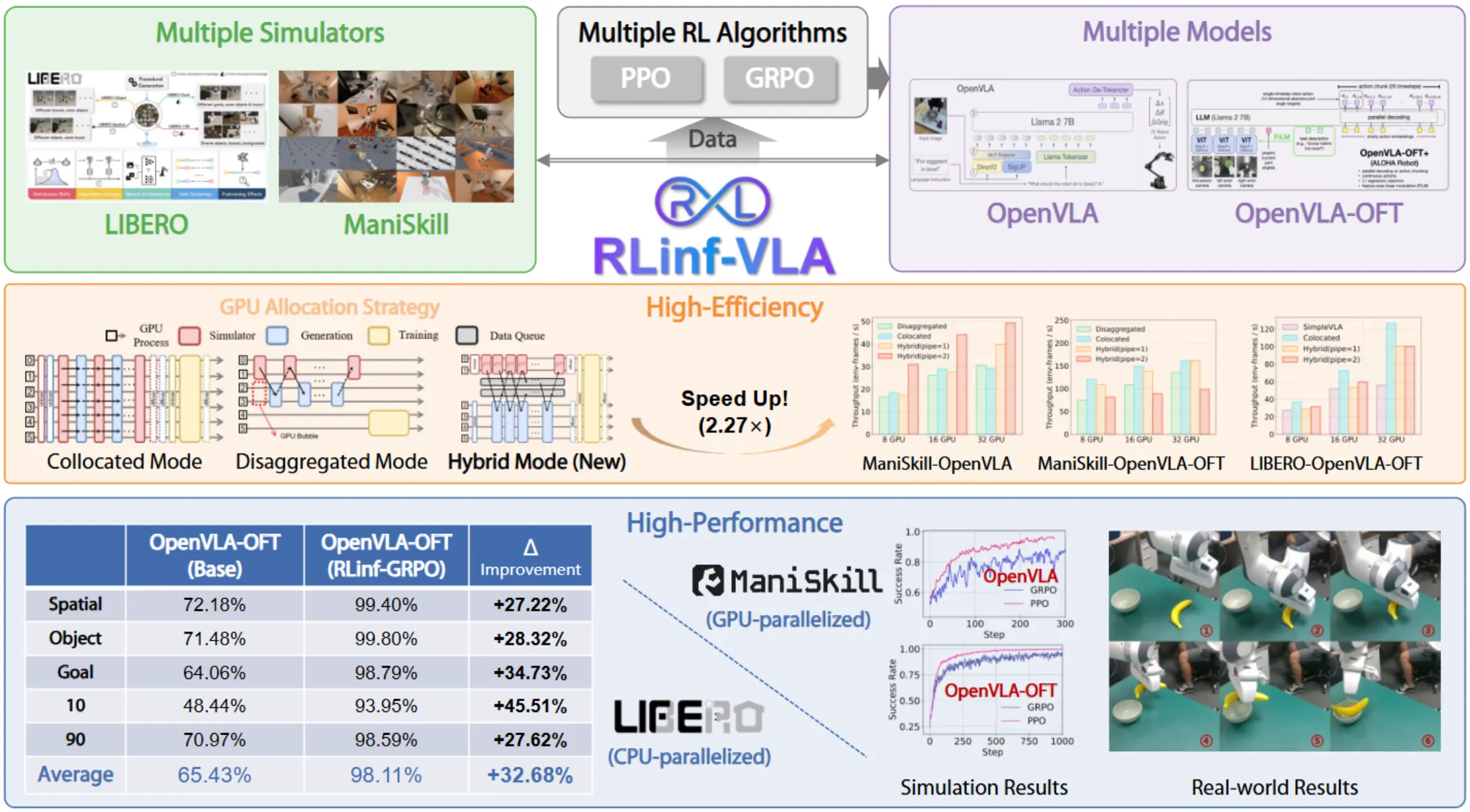
RLinf-VLA 是一个仿真的在线强化学习框架,支持了不同的仿真环境以及不同的模型,做了很多 Infra 相关的内容。本身从设计上完全 Flow Gym 的风格,并且支持了不同的 reset 以及强化学习方案。Engineering 以及 Infra 的内容总是对社区有价值的,尤其是做的还不错。详细的内容可以去他们的仓库或者论文中看。
IntentionVLA#
使用意图推断作为中间表征的 Pi-like VLA
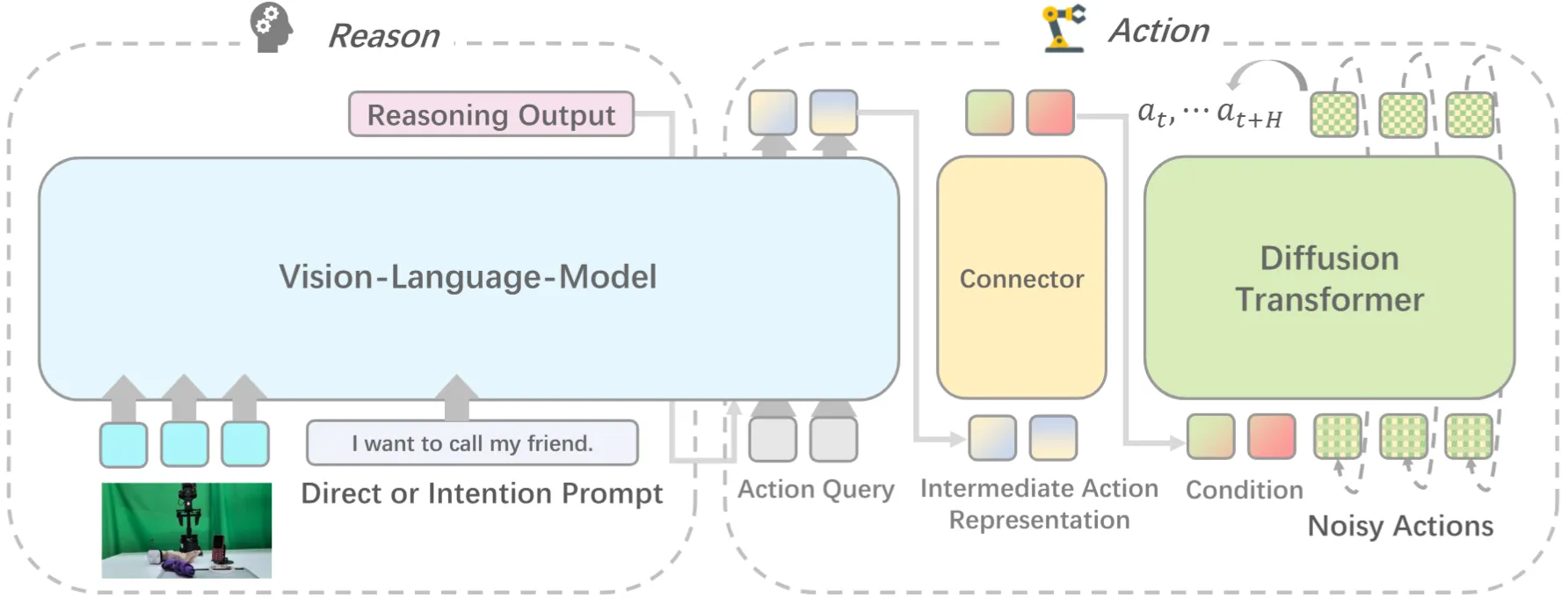
IntentionVLA 本身比较直观,就是标注了一系列的意图推断 CoT 作为预训练数据,训练了一下类似的模型具身推理能力,之后后面接一个 Connector 以及 DP,最后输出 Action Chunk。文章的 Limitation 在于 Stage 2 没有引入 Co-Training,做的时间其实比类似的论文,比如说 InternVLA-M1 要晚,Co-Training 的缺失意味着后续训练中可能存在的灾难性遗忘。
X-VLA#
使用 Soft Prompt 进行预训练并且比较 Work 的轻量 VLA
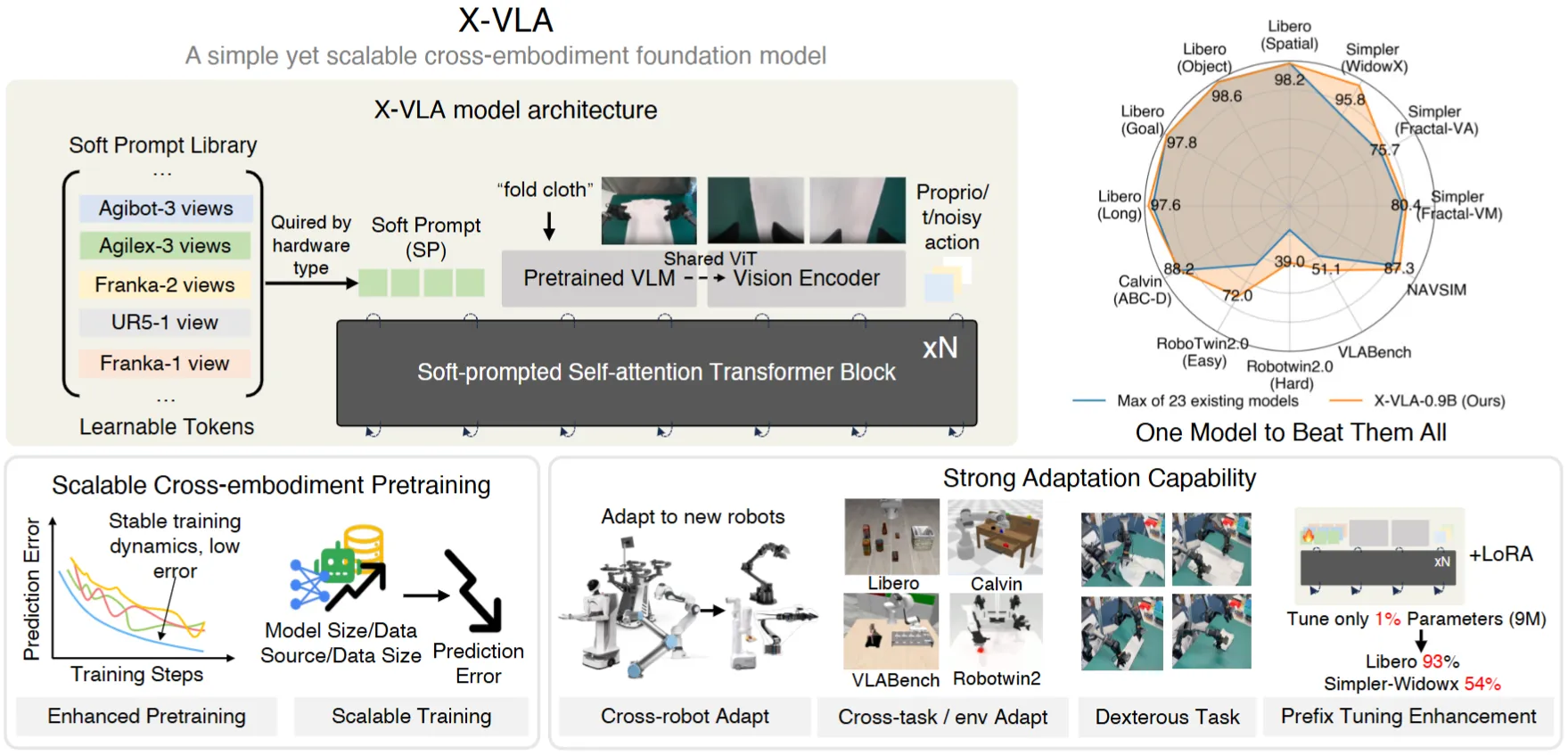
X-VLA 与其说使用了 Soft-prompt 进行了预训练,不如说是一个集大成之作,各种的调参技巧,使得一个轻量的 VLA 可以屠榜各种的 Benchmark。本身的 Codebase 也很不错,详细的可以到论文中看一下。在这里简单概括,大概的 Trick 包括 Custom LR, Heterogeneous PT, Action alignment, Intension abstraction, Balanced data sampling,还有很多很多,都是满满的细节。本身的训练还是多阶段,先预训练,之后到每一个 Bench 去微调。
Spatial Forcing#
使用 VGGT 的 Feature 对齐 VLA 中的 VLM 层
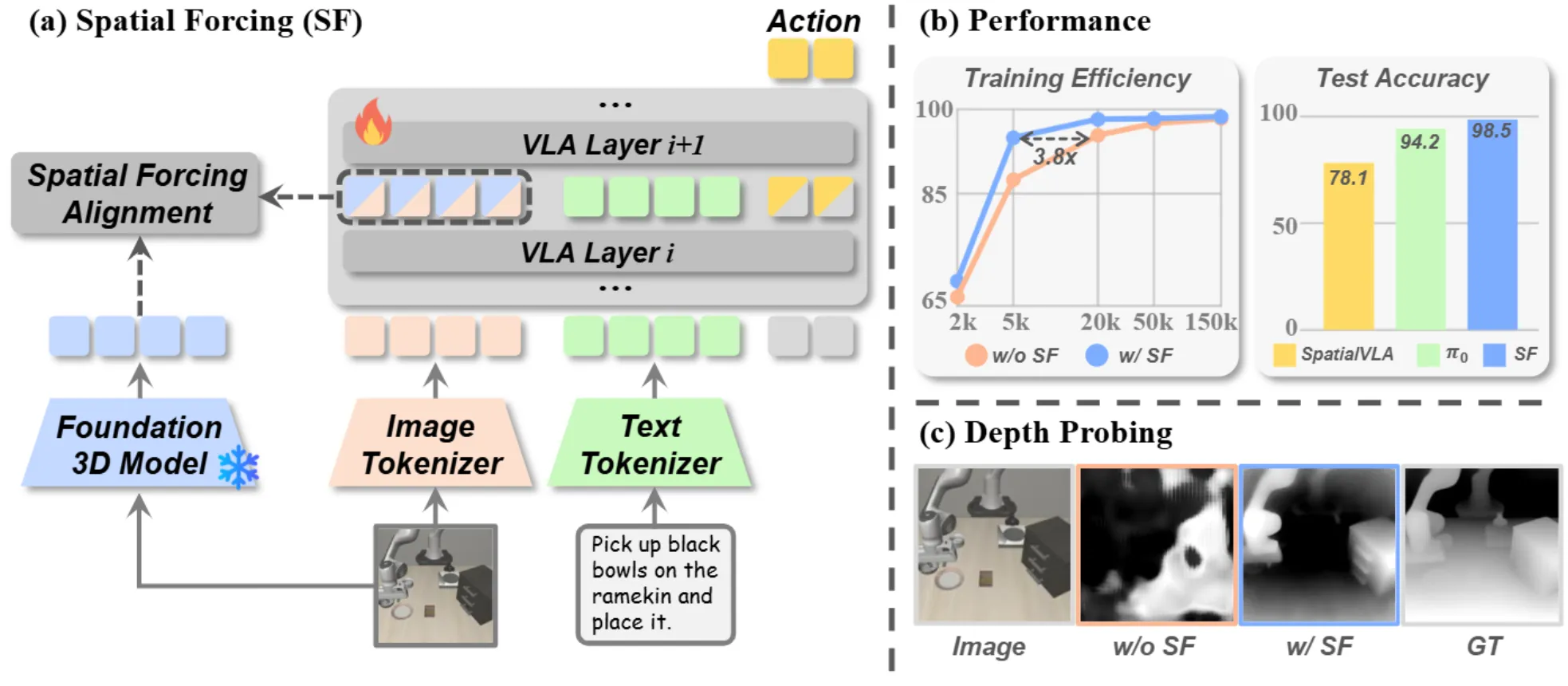
Spatial Forcing 本身使用 VGGT Feature 对齐 VLA 中 VLM 的中间层,并且进行训练。对于 SF 方法来说,疑点其实比较明显,假如说为了引入空间信息,也不想破坏之前的 VLM(这就是为什么不将 Feature 作为 VLM 输入),那么直接放到 VLM 和 DP 的连接的地方来 Concat 一下不也合理吗?仅仅通过 VGGT 的先验来训练所谓的 3D VLM 似乎是不现实的,从结果上来看 SF 似乎也只是验证了作为模型的能力,而不是某些在对空间感知有需求的任务中有效。总体来说比较中规中矩的论文。
BridgeVLA#
Two stage 训练的 3D VLA,用 Heatmap 预测 Transform,MLP 输出其他内容
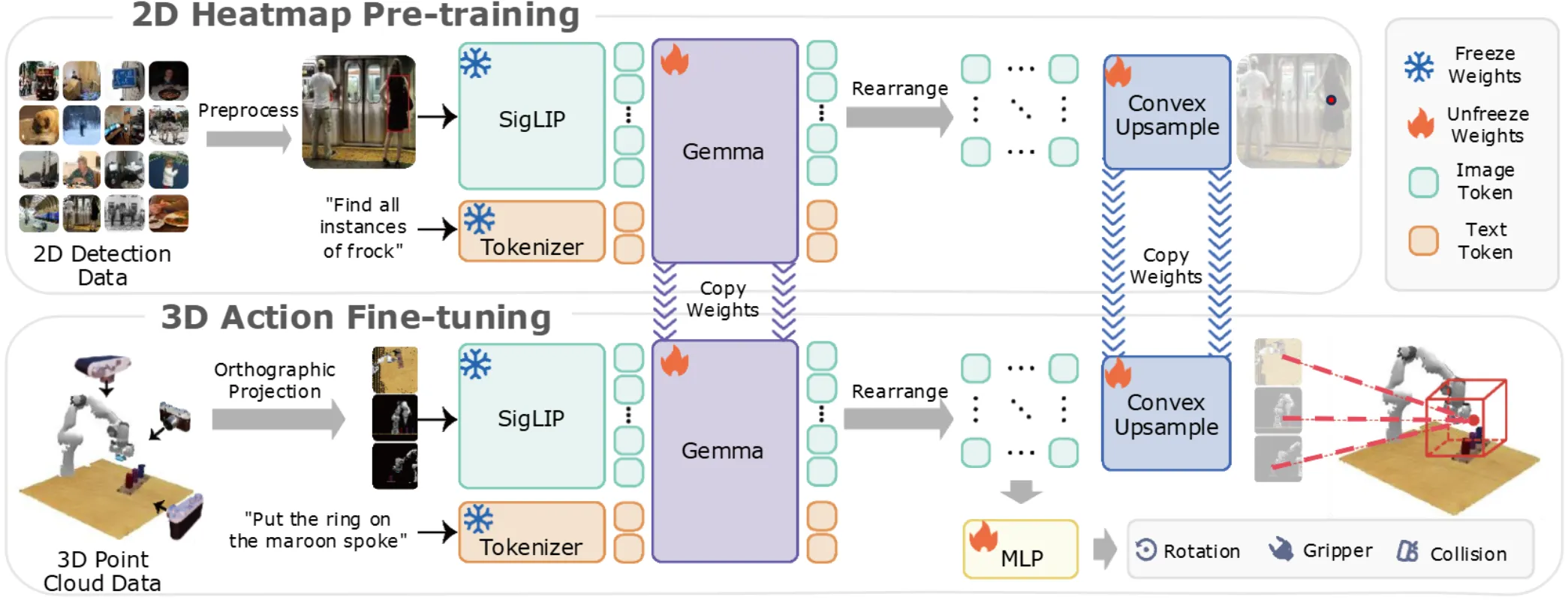
BridgeVLA 算是 3D VLA 里面比较早去做的,本身也是在 RoboTwin 的挑战赛里面获得了不错的名次。模型本身还是两阶段训练,每个阶段本质上都是希望 VLM 直接输出 Heatmap,算是把常规的 BBox 输出 soft 了一下。第一阶段在 RoboPoint 上预训练 Grounding 能力,之后第二阶段在真实数据集上后训练,本身输入点云从三个视角获得的投影图,预测 Heatmap 并且重投影得到新的 EE Pose 的 Translation,至于 Orientation 以及 Gripper 之类的内容,则把全部的信息一起输入给 MLP 预测。
虽然说比较早期,但是还是有几个槽点。首先就是整体的处理方法似乎不是很优雅,假如说全部的信息都可以通过 Translation 的求法来得到,那么可能会好很多,但是本身 3D 的 Translation 自由度也不是很高,本身 Heatmap 并没有解决太多的问题。比较偏向于显式的方法会带来各种 limitation,不过似乎收益也不显著。其次,似乎预训练的效果只在真机上进行了验证,效果也不显著。不过总体来说还是不错的。
RoVer#
引入 Reward Model 进行测试时验证
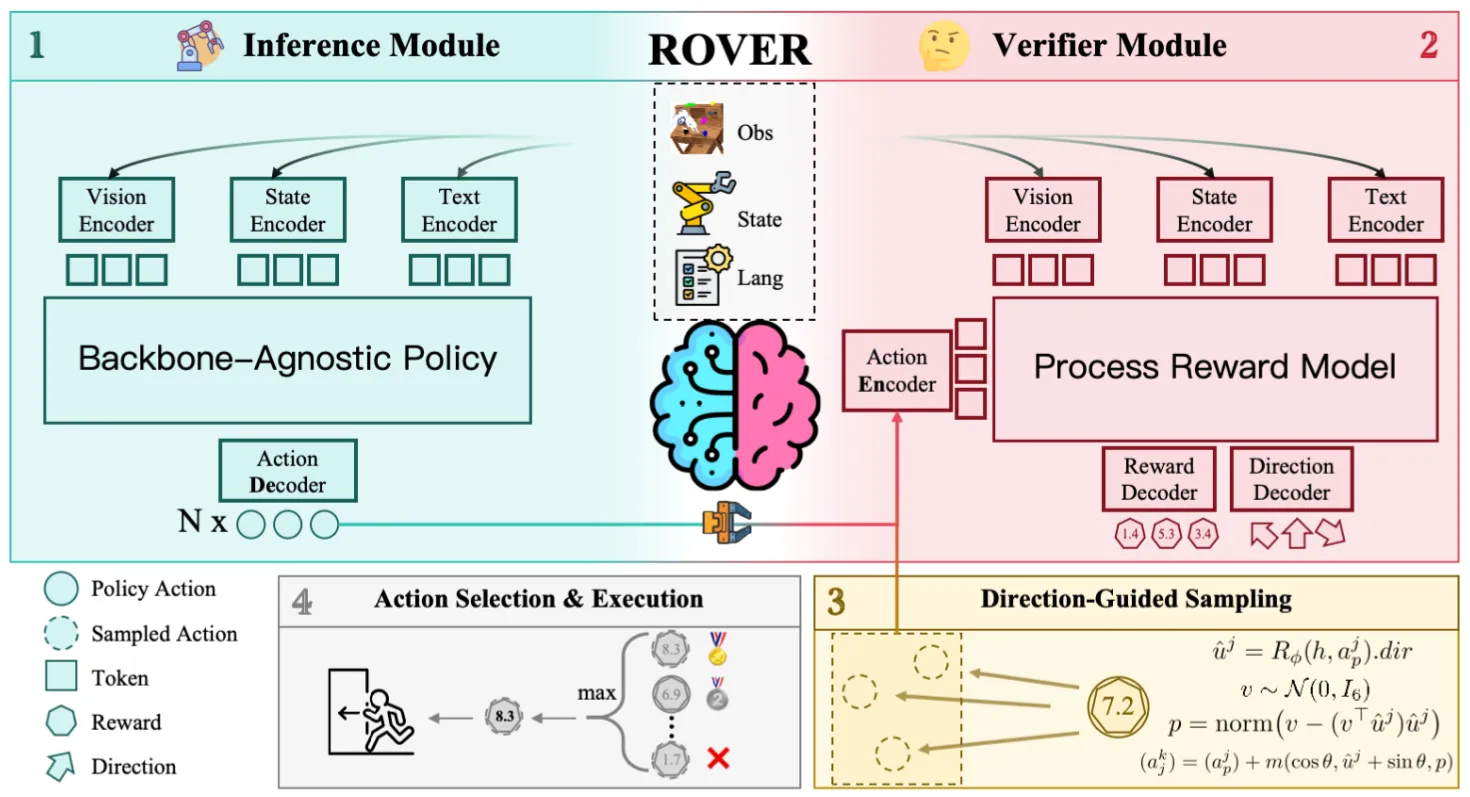
RoVer 的故事描述了这样的内容,对于一个已经预训练的 VLA 模型,输出轨迹并且采样为多条随机轨迹,在后面接入 RoVer,对于输入的轨迹以及 VL 信息,输出对应的分数进行打分。内容比较直观。所谓的 Test-time scaling 其实就是搞出来多条轨迹让 RoVer 选择最好的。
VLA-0#
VLM 直接输出文本 Action 的 VLA
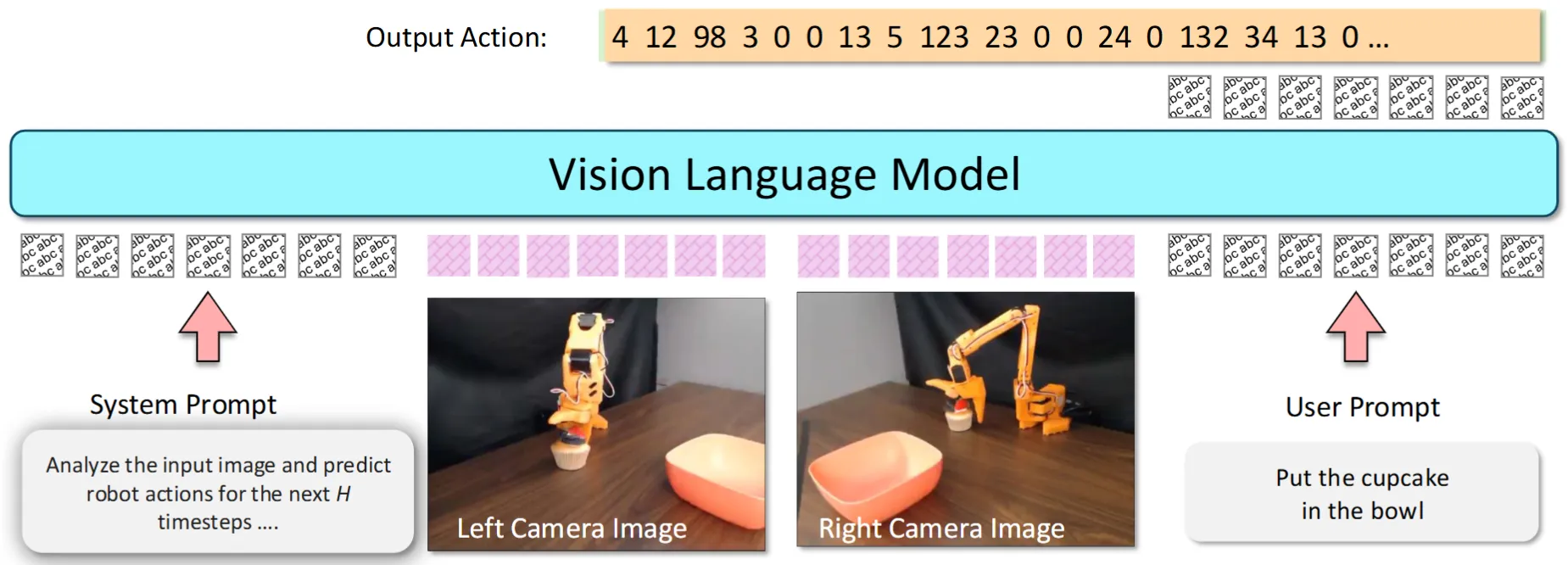
VLA-0 方法非常简单直接,直接用 Qwen-VL-2.5 3B 来直接输出文本形式的 Action,效果意外不错,算是很有趣的大胆尝试,一个大家都认为最简单且无意义的范式,意外性能不错。
InternVLA-M1#
使用空间先验进行 Co-training 的 VLA
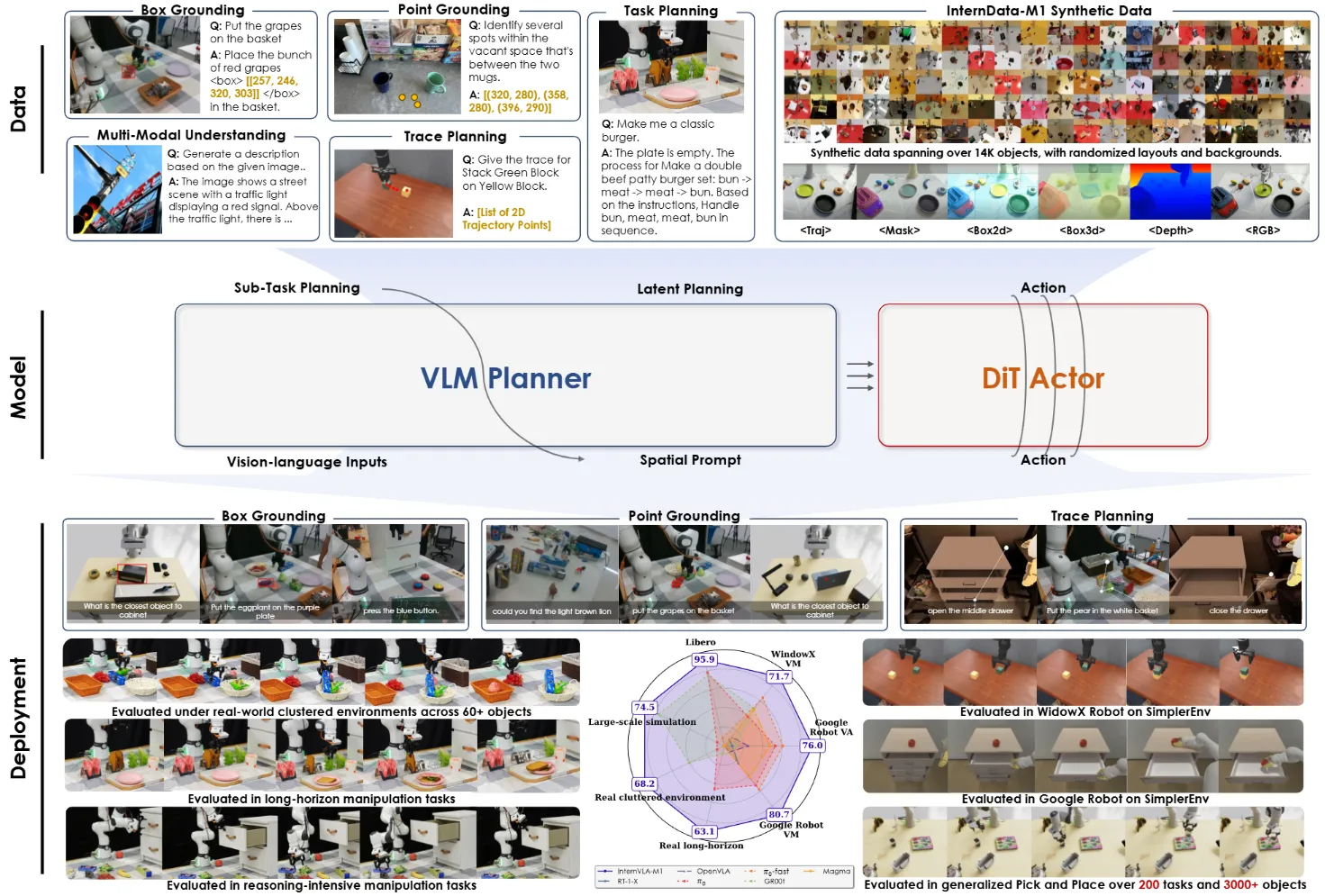
InternVLA-M1 是一篇技术报告,其中主要围绕构建 InternVLA-M1 展开,在本身的 VLA 内容基础上包括了非常充分的实验,以及数据管线的介绍。从本质上应该算是 3 分之作,不过后面会介绍其相关的社区贡献,以及笔者还是参与其中,综合 4 分。
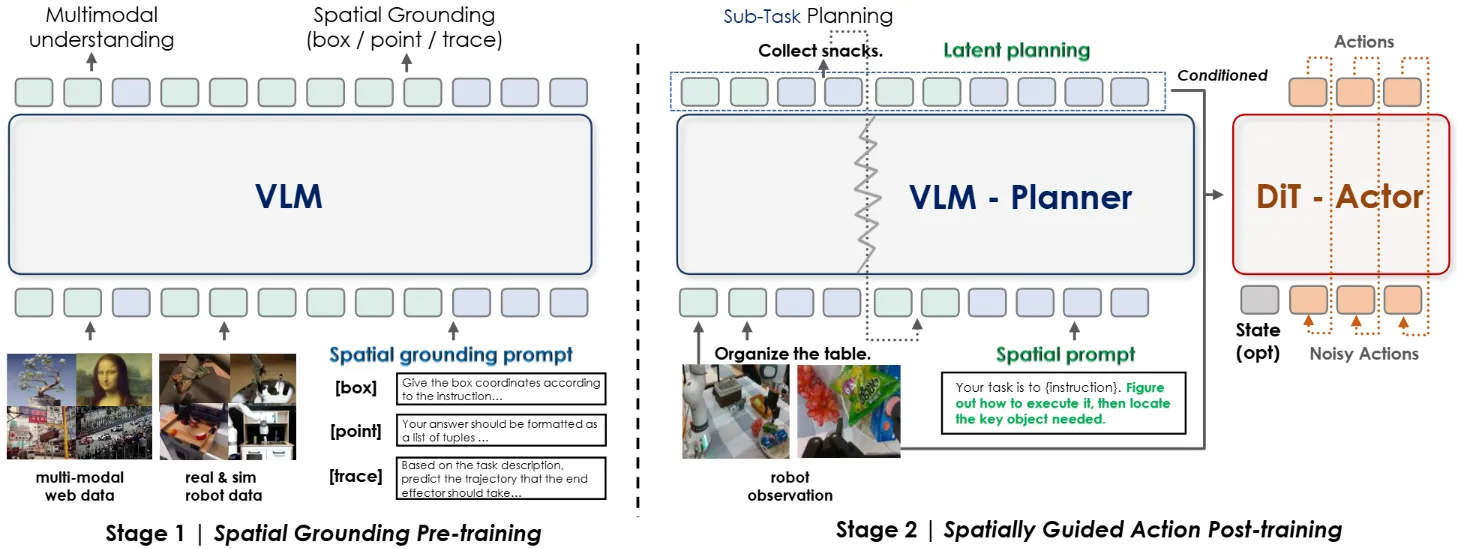
本身 InternVLA-M1 采用经典的 VLM + DP 的 Pi-like 方案,并且使用 Latent Planning,即 VLM 输出的 Latent embedding 作为 DP 的 condition,之后使用 Qformer 来施加 Condition。InternVLA-M1 采用经典二阶段训练,一阶段训练 VLM 的空间能力,二阶段训练 VLA。InternVLA-M1 之所以经典,在于是较早(且开源)的在二阶段训练过程中保留了 Co-training,从而保留 VLM 的能力,并且加速了 VLA 的收敛速度等内容。
在此之后,InternVLA-M1 的 Codebase 衍生了 StarVLA 项目,在 InternVLA-M1 的基础上,Cleanup 了非常好用的 VLM + VLA 训练框架,使用非常优雅的方式基于 Qwen 支持了不同的结构,比如说 Pi-like, GR00t-like 或者 OFT-like。

除此之外,InternVLA-M1 基于 GenManip 作为数据引擎以及闭环验证的仿真器,合成了大量的数据并且进行了 Scaling 测试,即在 200 个彼此完全不同的 Cluster 场景下进行测试,并且在数十万的仿真数据上进行训练。GenManip 目前也是基于 Isaac Sim 开源且最为灵活的仿真闭环平台之一,支持非常便捷的床加你数据生成或者测试任务,以及丰富的社区支持。
QDepth-VLA#
引入了 Depth Expert 的 Pi-like VLA
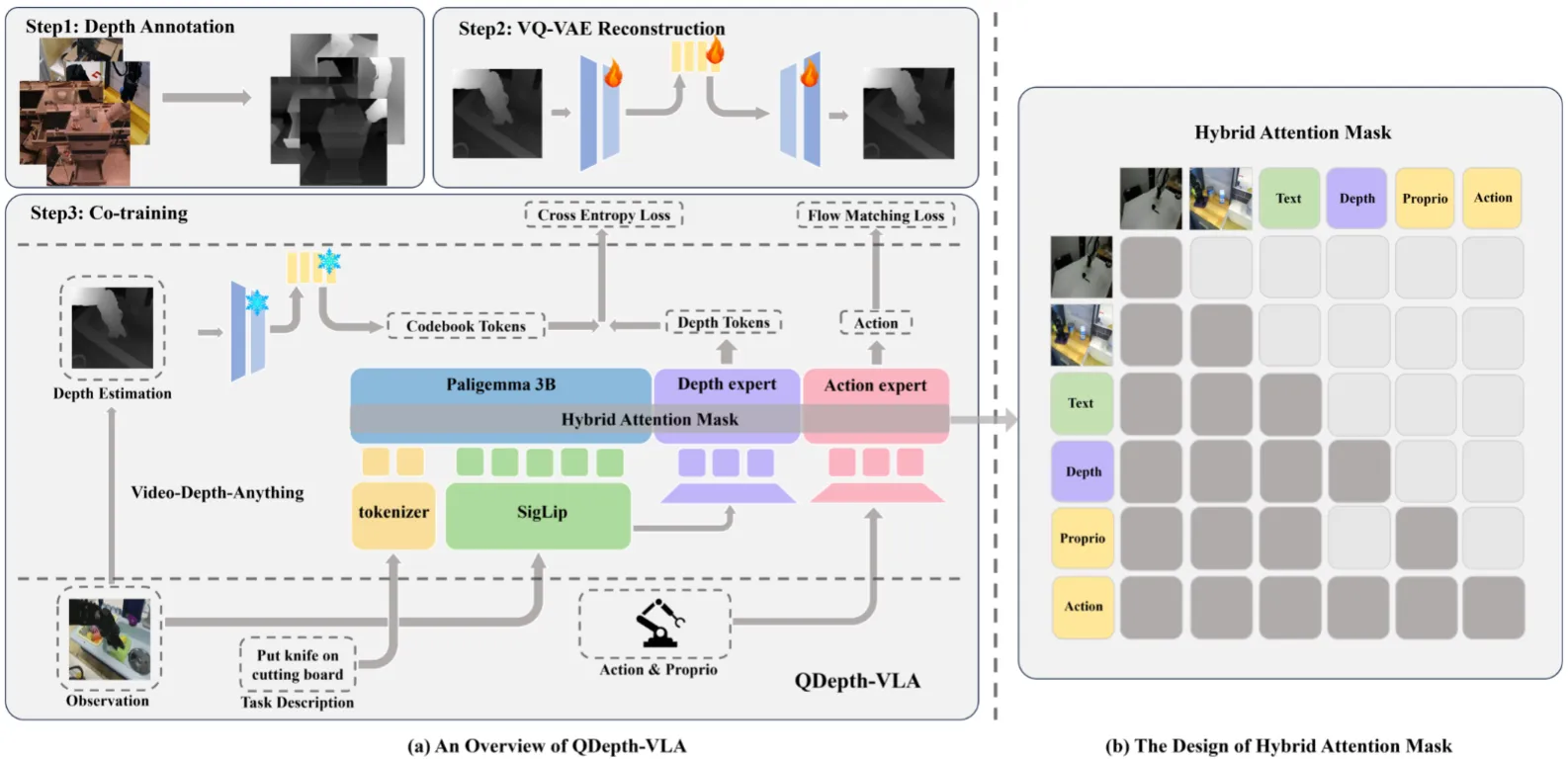
QDepth-VLA 的方法比较直观,从图中也可以直接理解。首先其训练了一个 VQVAE 来理解 Depth 信息,创建 Depth Token,本身 Depth 信息由 ViDA 处理正常视频得到。之后在 Pi 中加入一个新的 MoT 负责预测 Depth Token,和其他 Transformer 共同构成 MoT。问题在于为什么不直接使用 ViDA 的 Feature 而是要用 VAE,究竟是不是有那么大的意义(从另一方面,对于类似 F1-VLA 的模型,中间是 World Model Expert,是预测 Token 还是预测图片,可能有类似的规律),但是似乎消融实验中没有给出。总体还算可以。
WoW#
使用语言纠正来优化预测的 World Model
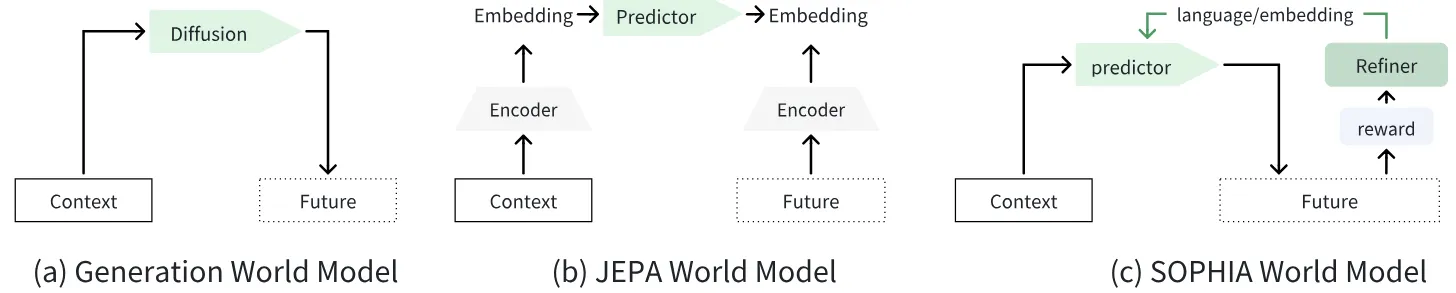
WoW 本身名字其实很大,也就是 World-Omniscient World-Model,论文写得像是综述也像是方法。 细看下来主要在 training recipe 方面的优化主要是加入了一个 Refiner 来输出所谓的纠正信号,本质上就是学习以及添加了一个 Condition。WoW 有着和 Genie Envisioner 类似的设计,可以同时作为 Base, Actor, Simulator 来使用。
Goal-VLA#
使用 World Model 生成图像 + Modular Framework 进行 Zero-shot 操作

Goal-VLA 尽管名字中包含 VLA,但是事实上更加类似于早期 CoPA 以及 MOKA 的模块化设计。总体来说的方法在图中可见,主要就是使用生成模型生成 Goal image,然后对于 current image 以及 goal image 进行 semantic 分割,之后预测光流以及预测 Grasp Pose,从而进行操作。
方法的 limitation 比较显然,首先是对于 Articulation 以及其他灵巧操作缺乏泛化性,这是模块化方法的通病;同时其实我没有太 get 到光流的意义是什么,笔者在早期复现了 MOKA 以及 CoPA,感觉只需要 contact grasp pose 就已经足够了。
MiMo-Embodied#
Embodied VLM
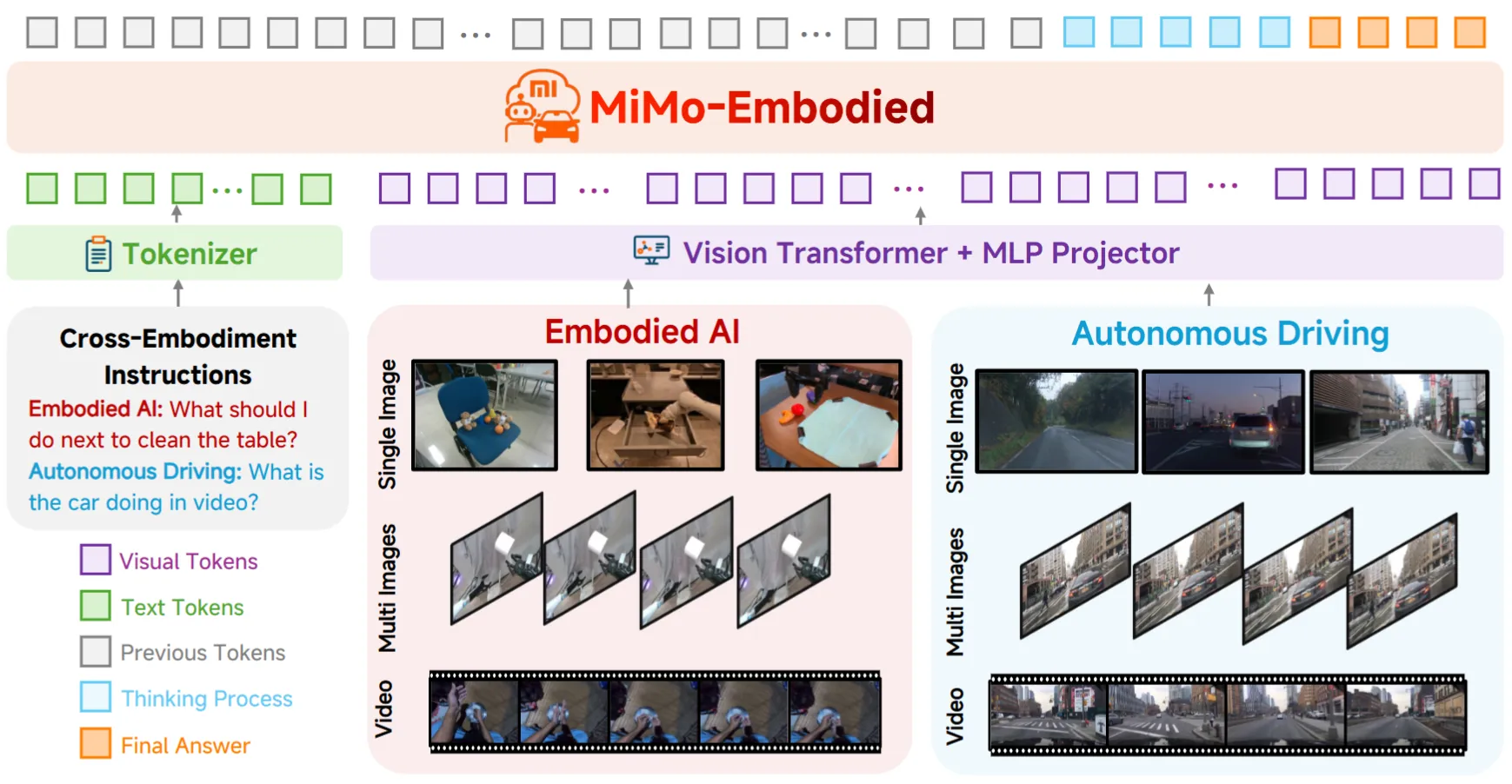
小米出品的 Embodied VLM。对于相关论文基本上以数据工程为主,在这里不过多赘述。类似于 RoboBrain。
VLA-Cache#
通过自适应缓存进行 VLA 推理加速
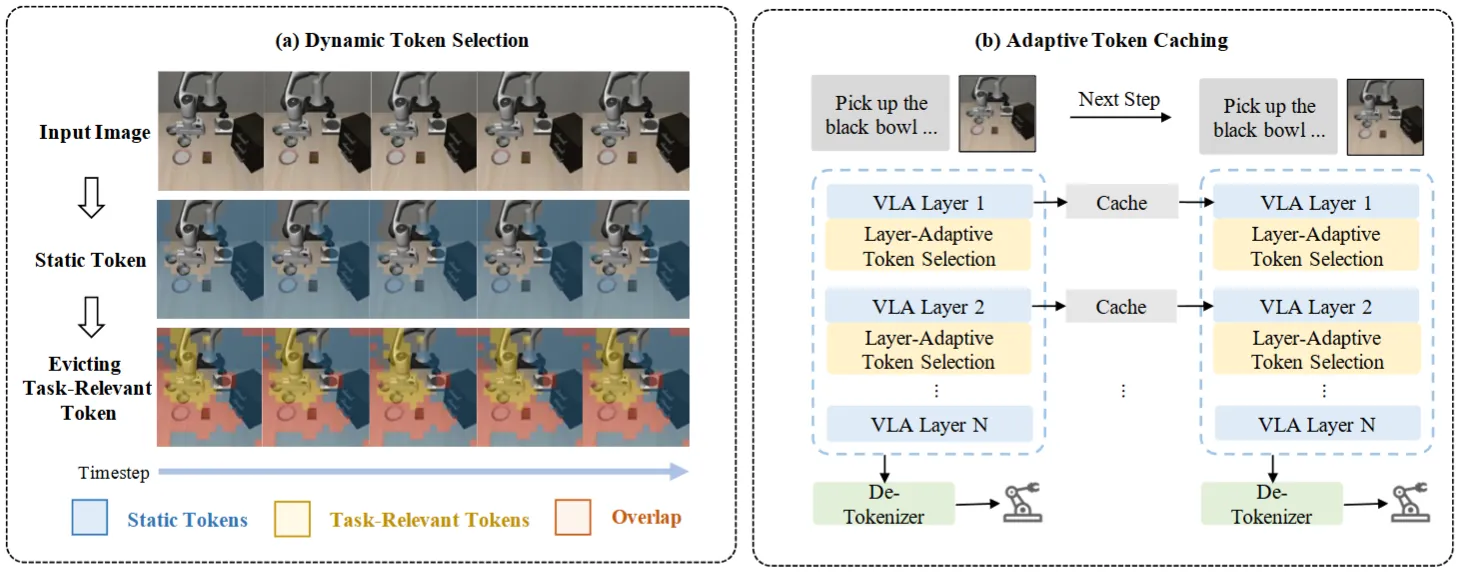
VLA-Cache 本身的方法非常直观,就是通过一个缓存模块来缓存 embedding,从而加速 VLA 的推理,本身利用了 VLA 推理时候图像输入的大量不变内容(也就是说在动态场景下其实适用性一般)。本身包括两方面的 A+B,动态 Token 选择在跨帧时重用静态 token 同时保留任务相关 token;自适应 Token 缓存根据注意力模式动态调整每个解码器层的重用比例。比如说静态 Token 其实是对于 Image 进行 pixel-wise 的比较来获得相似度,从而选择所谓的静态 Token。以及根据注意力的熵来决定重用比例,即随着注意力变得更加聚焦,较少的 token 可能需要重新计算。
总体来说 VLA-Cache 算是在 VLA 领域中比较少见做加速的方法,尽管内容比较直观。期待后续更多相关的工作。
GigaBrain-0#
使用了 World Model 数据的 Pi-like VLA

GigaBrain-0 本身比较直观,从图中就可以看出,基本上完全就是 Pi-0.5 的故事。其中可能对于 workflow 有所优化,在其中加入了 World Model 合成的数据作为补充,以及 Depth 数据的输入。本身偏向于工程实现为主,还算可以。
RoboMemory#
基于动态图谱以及动态知识图谱的 System 2 Agent
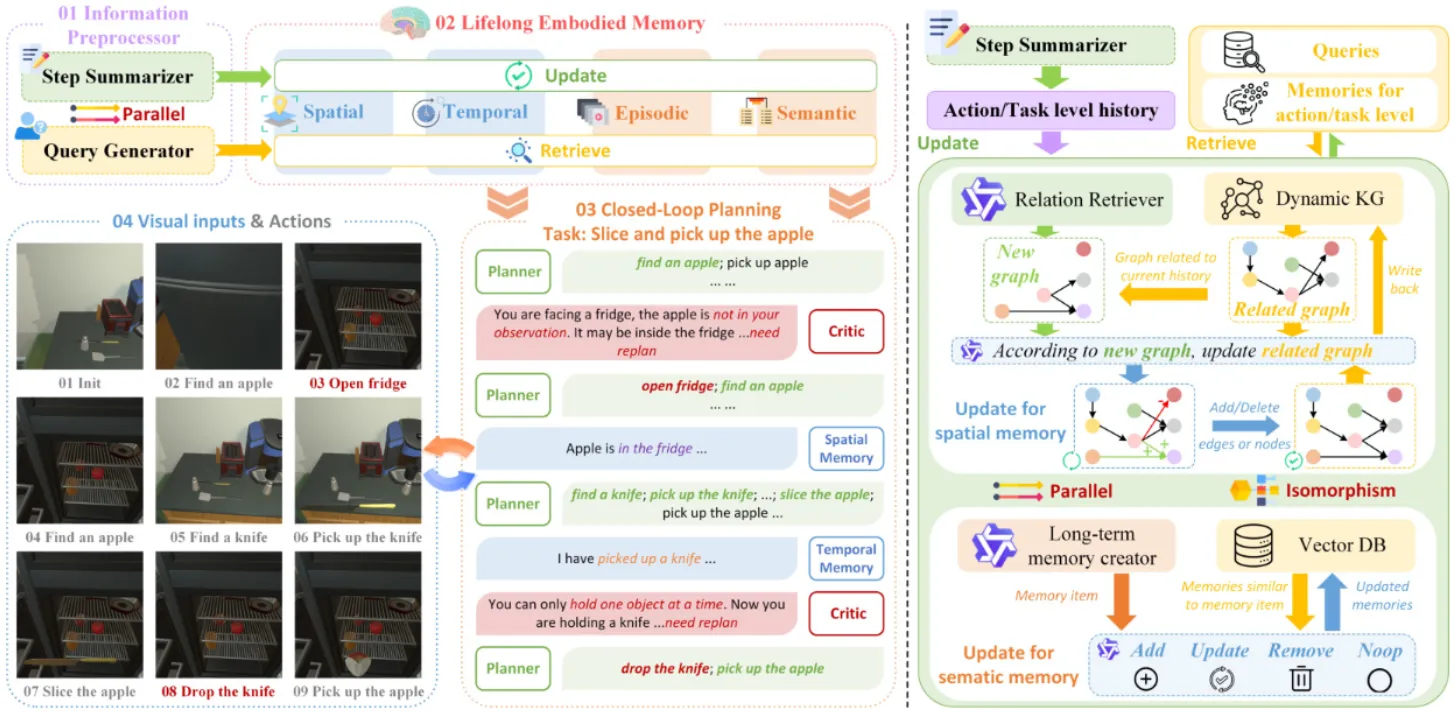
RoboMemory 本身讲了一个仿生学的故事,所谓若干脑中结构,本身是一个使用 RAG 之类的内容,可以支持动态记忆并且包含一个 Low Level 的 Skill Bank 的 Agent,可以调用下游的 Pi 以及 SLAM。这种看似体系的论文实际上只能通过大量的调试得到 Demo,不过本身看上去比较完整,还可以。
LIBERO#
Manipulation 经典 Benchmark

LIBERO 本身是一个比较经典的 Manipulation Benchmark,在 Mujoco 上面涉及了一些 Randomization 以及 Long-horizon Task。不过本身 LIBERO 的训练数据和测试的 Gap 不算大,并不是足够 Challenge,也是比较早期工作的局限性之一,因此目前基本上已经被现代方法刷爆(大约 99% 成功率)。尽管如此,其对于不同维度的分类分析依然具有参考价值。
LIBERO-Plus#
在 LIBERO 的基础上加入更多扰动的 Benchmark
LIBERO-Plus 是非原班人马做出的后续工作。正如上文提及,LIBERO 事实上具有若干局限性,也就是数据和测试样例的区别不大,反映在 VLA 用户的需求上,直观的一点就是不够难。Plus 通过物体布局、相机视角、机器人初始状态、语言指令、光照条件、背景纹理以及传感器噪声等维度进行了大量的扰动,从而使得 LIBERO-Plus 更加具有挑战性。分析这些内容对于模型造成的不同程度的影响也比较有趣。
Simpler Env#
Real2Sim Benchmark
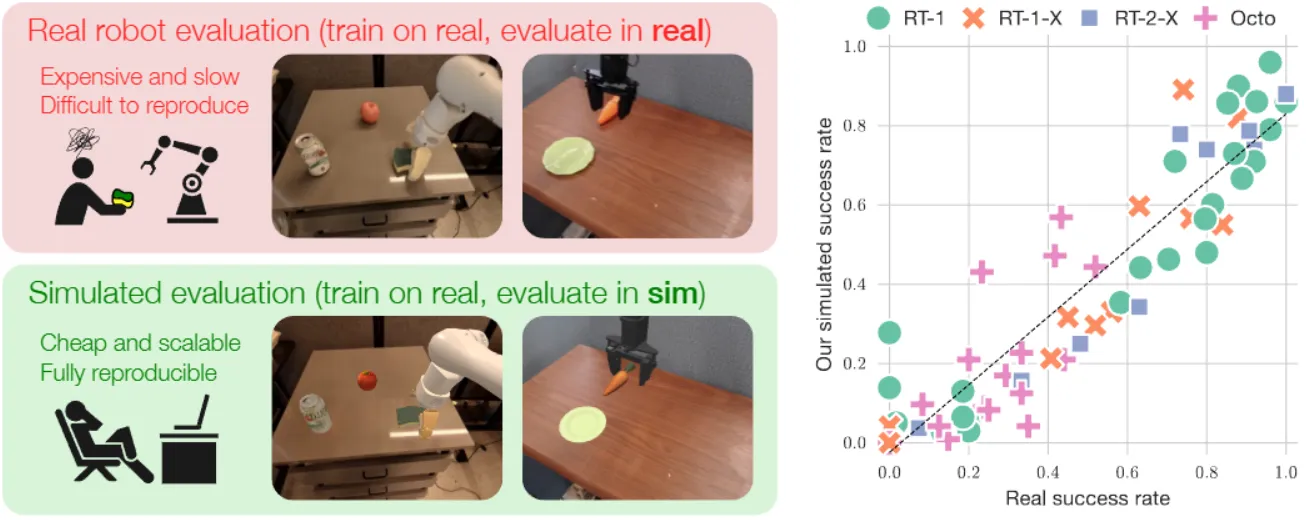
Simpler Env 可以说是当今时代下最为严谨的 Manipulation Benchmark 之一,对于物理相关的仿真进行了大量的对齐,以及对于各种机械臂的参数进行了对齐。本身 Simpler 不提供仿真数据,而是直接使用真机数据,大量的对齐可以使得 Simpler 获得上图中所显示的真机和仿真性能对齐的效果。从此 Real2Sim 准确率成为仿真 Benchmark 非常 Highlight 的 Feature 之一。
RoboOmni#
全模态 Pi-like VLA
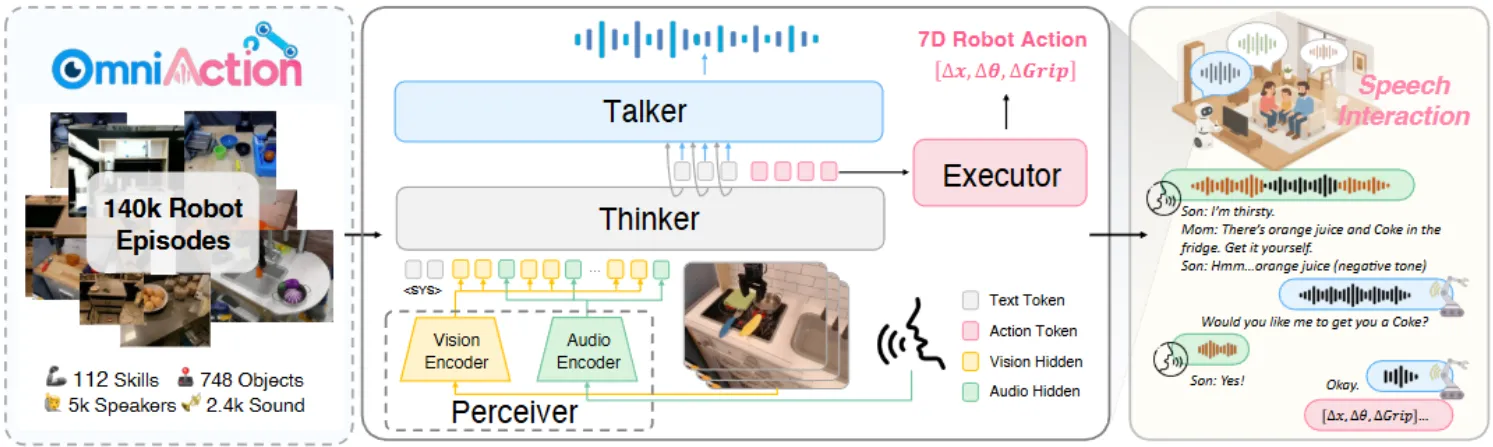
RoboOmni 本身可以使用 Audio encoder 以及 RGB encoder 进行联合训练,Pi-like 的结构,并且可以输出 Action 或者 Audio。不过事实上所谓的 Omni 只是起到了交互体验的提升,从论文的贡献度上来看意义不大,因此的语音数据带来了模型更大的学习成本,进而可能得不偿失。算是还可以的探索型论文。